Code
library(tidyverse)
library(kableExtra)
library(scales)
library(forecast)
library(cmapplot)
knitr::opts_chunk$set(warning = FALSE, message = FALSE)
theme_set(theme_classic() )Not correct yet.
Moved from the Calculating the Fiscal Gap quarto doc and it became more of an ordeal than I thought it would be.
library(tidyverse)
library(kableExtra)
library(scales)
library(forecast)
library(cmapplot)
knitr::opts_chunk$set(warning = FALSE, message = FALSE)
theme_set(theme_classic() )exp_temp <- read.csv("data/exp_temp.csv") %>%
mutate(agency = as.character(agency),
object = as.character(object),
object = str_pad(object, side = "left", 4, pad = "0"),
sequence = as.character(sequence),
sequence = str_pad(sequence, side = "left", 2, pad = "0"),
type = as.character(type),
type = str_pad(type, side = "left", 2, pad = "0"),
appr_org = as.character(appr_org),
appr_org = str_pad(appr_org, side = "left", 2, pad = "0"),
fund = as.character(fund),
fund = str_pad(fund, side = "left", 4, pad = "0"),
fund_ioc = as.character(fund_ioc))
exp_temp <- exp_temp %>%
mutate(eehc = ifelse(
# group insurance contributions for 1998-2005 and 2013-present
fund == "0001" & (object == "1180" | object =="1900") & agency == "416" & appr_org=="20", 0, 1) )%>%
mutate(eehc = ifelse(
# group insurance contributions for 2006-2012
fund == "0001" & object == "1180" & agency == "478"
& appr_org=="80", 0, eehc) )%>%
# group insurance contributions from road fund
# coded with 1900 for some reason??
mutate(eehc = ifelse(
fund == "0011" & object == "1900" &
agency == "416" & appr_org=="20", 0, eehc) ) %>%
mutate(expenditure = ifelse(eehc=="0", 0, expenditure)) %>%
mutate(agency = case_when( # turns specific items into State Employee Healthcare (agency=904)
fund=="0907" & (agency=="416" & appr_org=="20") ~ "904", # central management Bureau of benefits using health insurance reserve
fund=="0907" & (agency=="478" & appr_org=="80") ~ "904", # agency = 478: healthcare & family services using health insurance reserve - stopped using this in 2012
TRUE ~ as.character(agency))) %>%
mutate(agency_name = ifelse(
agency == "904", "STATE EMPLOYEE HEALTHCARE", as.character(agency_name)),
in_ff = ifelse( agency == "904", 1, in_ff),
group = ifelse(agency == "904", "904", as.character(agency)))
# creates group variable
# Default group = agency number
healthcare_costs <- exp_temp %>% filter(group == "904")
healthcare_costsexp_temp <- exp_temp %>%
mutate(
agency = case_when(fund=="0515" & object=="4470" & type=="08" ~ "971", # income tax to local governments
fund=="0515" & object=="4491" & type=="08" & sequence=="00" ~ "971", # object is shared revenue payments
fund=="0802" & object=="4491" ~ "972", #pprt transfer
fund=="0515" & object=="4491" & type=="08" & sequence=="01" ~ "976", #gst to local
fund=="0627" & object=="4472"~ "976" , # public transportation fund but no observations exist
fund=="0648" & object=="4472" ~ "976", # downstate public transportation, but doesn't exist
fund=="0515" & object=="4470" & type=="00" ~ "976", # object 4470 is grants to local governments
object=="4491" & (fund=="0188"|fund=="0189") ~ "976",
fund=="0187" & object=="4470" ~ "976",
fund=="0186" & object=="4470" ~ "976",
object=="4491" & (fund=="0413"|fund=="0414"|fund=="0415") ~ "975", #mft to local
fund == "0952"~ "975", # Added Sept 29 2022 AWM. Transportation Renewal MFT
TRUE ~ as.character(agency)),
agency_name = case_when(agency == "971"~ "INCOME TAX 1/10 TO LOCAL",
agency == "972" ~ "PPRT TRANSFER TO LOCAL",
agency == "975" ~ "MFT TO LOCAL",
agency == "976" ~ "GST TO LOCAL",
TRUE~as.character(agency_name)),
group = ifelse(agency > "970" & agency < "977", as.character(agency), as.character(group)))
transfers_long <- exp_temp %>%
filter(group == "971" | group == "972" | group == "975" | group == "976")
transfers_long %>%
group_by(agency_name, group, fy) %>%
summarize(expenditure = sum(expenditure, na.rm=TRUE) )%>%
ggplot() +
geom_line(aes(x=fy, y = expenditure, color=agency_name)) +
theme_classic()+
theme(legend.position = "bottom", legend.title=element_blank())+
labs(title = "Transfers to Local Governments",
caption = "Data Source: Illinois Office of the Comptroller")![]()
transfers <- transfers_long %>%
group_by(fy, group ) %>%
summarize(sum_expenditure = sum(expenditure)/1000000) %>%
pivot_wider(names_from = "group", values_from = "sum_expenditure", names_prefix = "exp_" )
debt_drop <- exp_temp %>%
filter(object == "8841" | object == "8811")
# escrow OR principle
#debt_drop %>% group_by(fy) %>% summarize(sum = sum(expenditure)) %>% arrange(-fy)
debt_keep <- exp_temp %>% mutate(agency = as.character(agency)) %>%
filter(fund != "0455" & (object == "8813" | object == "8800" ))
# examine the debt costs we want to include
#debt_keep %>% group_by(fy) %>% summarize(sum = sum(expenditure)) %>% arrange(-fy)
exp_temp <- anti_join(exp_temp, debt_drop)
exp_temp <- anti_join(exp_temp, debt_keep)
debt_keep <- debt_keep %>%
mutate(
agency = ifelse(fund != "0455" & (object == "8813" | object == "8800"), "903", as.character(agency)),
group = ifelse(fund != "0455" & (object == "8813" | object == "8800"), "903", as.character(group)),
in_ff = ifelse(group == "903", 1, as.character(in_ff)))
debt_keep_yearly <- debt_keep %>% group_by(fy, group) %>% summarize(debt_cost = sum(expenditure,na.rm=TRUE)/1000000) %>% select(-group)exp_temp <- read_csv("data/all_expenditures_recoded.csv") %>%
#exp_temp <- read.csv("data/exp_fy23_recoded_02April2024.csv") %>%
#exp_temp <- read.csv("data/exp_temp.csv") %>%
mutate(agency = as.character(agency),
object = as.character(object),
object = str_pad(object, side = "left", 4, pad = "0"),
sequence = as.character(sequence),
sequence = str_pad(sequence, side = "left", 2, pad = "0"),
type = as.character(type),
type = str_pad(type, side = "left", 2, pad = "0"),
appr_org = as.character(appr_org),
appr_org = str_pad(appr_org, side = "left", 2, pad = "0"),
fund = as.character(fund),
fund = str_pad(fund, side = "left", 4, pad = "0"))
# rev_temp <- read.csv("data/rev_temp.csv") %>%
# rev_temp <- read.csv("data/rev_fy23_recoded_02April2024.csv") %>%
rev_temp <- read_csv("data/all_revenue_recoded.csv") %>%
mutate(rev_type = as.character(rev_type),
agency = as.character(agency),
fund = str_pad(fund, side = "left", 4, pad = "0")) Dropping State CURE Revenue
The Fiscal Futures model focuses on sustainable revenue sources. To understand our fiscal gap and outlook, we need to exclude these one time revenues. GOMB has emphasized that they have allocated COVID dollars to one time expenditures (unemployment trust fund, budget stabilization fund, etc.). The fiscal gap, graphs,and CAGRs have been recalculated in the [Drop COVID Dollars] section below.
NOTE: The code chunk below only drops revenue sources with the source name of “Federal Stimulus Package” (which is the State and Local CURE revenue). Additional federal money went into other funds during the beginning of pandemic. Many departments saw increased grants and received other funds (e.g. funds)
rev_temp <- rev_temp %>%
mutate(covid_dollars = ifelse(source_name_AWM == "FEDERAL STIMULUS PACKAGE",1,0))
# rev_temp %>% filter(source_name_AWM == "FEDERAL STIMULUS PACKAGE") %>%
# group_by(fy) %>% summarize(Received = sum(receipts))If only sustainable revenues are included in the model, then the federal dollars from the pandemic response (CARES, CRSSA,& ARPA) should be excluded from the calculation of the fiscal gap.
The Fiscal Futures model focuses on sustainable revenue sources. To understand our fiscal gap and outlook, we need to exclude these one time revenues. GOMB has emphasized that they have allocated COVID dollars to one time expenditures (unemployment trust fund, budget stabilization fund, etc.). The fiscal gap, graphs,and CAGRs have been recalculated in the [Drop COVID Dollars] section below.
NOTE: I have only dropped revenue with a source name =
Federal Stimulus Package. Federal money went into other funds during the beginning of pandemic. All additional money for medicaid reimbursements and healthcare provider funds were not considered “Federal Stimulus Package” in the data and were not dropped.
fund 0628 is essential government support services. Money in the fund is appropriated to cover COVID-19 related expenses. It should be included in our analytical frame based on criteria 2 and6 — the fund supports an important state function about public safety, which would have to be performed even the fund structure were not existed. Public safety is supported by a combination of departments and boards, including IL Emergency Management Agency, which is the administering agency of the fund.
Education Stabilization Fund
ESSER 1, 2, and 3
CSLFRF (State and Local CURE)
Provider Relief Fund
Coronavirus Relief Fund (CRF)
Consolidated Appropriations Act 2020
Families First Coronavirus Response Act
Paycheck Protection Program and Health Care Enhancement Act
Need to recreate ff_exp and ff_rev totals without stimulus dollars.
ff_rev <- rev_temp %>%
mutate(rev_type_new = str_pad(rev_type_new, 2, "left", pad = "0")) %>%
group_by(rev_type_new, fy) %>%
summarize(sum_receipts = round(sum(receipts, na.rm=TRUE)/1000000 )) %>%
pivot_wider(names_from = "rev_type_new", values_from = "sum_receipts", names_prefix = "rev_")
ff_rev <- mutate_all(ff_rev, ~replace_na(.,0))
rev_long <- pivot_longer(ff_rev, rev_02:rev_78, names_to = c("type","Category"), values_to = "Dollars", names_sep = "_") %>%
rename(Year = fy) %>%
mutate(Category_name = case_when(
Category == "02" ~ "INDIVIDUAL INCOME TAX" ,
Category == "03" ~ "CORPORATE INCOME TAX" ,
Category == "06" ~ "SALES TAX" ,
Category == "09" ~ "MOTOR FUEL TAX" ,
Category == "12" ~ "PUBLIC UTILITY TAX" ,
Category == "15" ~ "CIGARETTE TAXES" ,
Category == "18" ~ "LIQUOR GALLONAGE TAXES" ,
Category == "21" ~ "INHERITANCE TAX" ,
Category == "24" ~ "INSURANCE TAXES&FEES&LICENSES" ,
Category == "27" ~ "CORP FRANCHISE TAXES & FEES" ,
Category == "30" ~ "HORSE RACING TAXES & FEES", # in Other
Category == "31" ~ "MEDICAL PROVIDER ASSESSMENTS" ,
Category == "32" ~ "GARNISHMENT-LEVIES" , # dropped
Category == "33" ~ "LOTTERY RECEIPTS" ,
Category == "35" ~ "OTHER TAXES" ,
Category == "36" ~ "RECEIPTS FROM REVENUE PRODUCING",
Category == "39" ~ "LICENSES, FEES & REGISTRATIONS" ,
Category == "42" ~ "MOTOR VEHICLE AND OPERATORS" ,
Category == "45" ~ "STUDENT FEES-UNIVERSITIES", # dropped
Category == "48" ~ "RIVERBOAT WAGERING TAXES" ,
Category == "51" ~ "RETIREMENT CONTRIBUTIONS" , # dropped
Category == "54" ~ "GIFTS AND BEQUESTS",
Category == "57" ~ "FEDERAL OTHER" ,
Category == "58" ~ "FEDERAL MEDICAID",
Category == "59" ~ "FEDERAL TRANSPORTATION" ,
Category == "60" ~ "OTHER GRANTS AND CONTRACTS", #other
Category == "63" ~ "INVESTMENT INCOME", # other
Category == "66" ~ "PROCEEDS,INVESTMENT MATURITIES" , #dropped
Category == "72" ~ "BOND ISSUE PROCEEDS", #dropped
Category == "75" ~ "INTER-AGENCY RECEIPTS ", #dropped
Category == "76" ~ "TRANSFER IN FROM OUT FUNDS", #other
Category == "78" ~ "ALL OTHER SOURCES" ,
Category == "79" ~ "COOK COUNTY IGT", #dropped
Category == "98" ~ "PRIOR YEAR REFUNDS", #dropped
T ~ "Check Me!"
) )%>%
mutate(Category_name = str_to_title(Category_name))
exp_temp <- read_csv("data/all_expenditures_recoded.csv") %>%
#exp_temp <- read.csv("data/exp_fy23_recoded_02April2024.csv") %>%
#exp_temp <- read.csv("data/exp_temp.csv") %>%
mutate(agency = as.character(agency),
object = as.character(object),
object = str_pad(object, side = "left", 4, pad = "0"),
obj_seq_type = as.character(obj_seq_type),
sequence = as.character(sequence),
sequence = str_pad(sequence, side = "left", 2, pad = "0"),
type = as.character(type),
type = str_pad(type, side = "left", 2, pad = "0"),
appr_org = as.character(appr_org),
appr_org = str_pad(appr_org, side = "left", 2, pad = "0"),
fund = as.character(fund),
fund = str_pad(fund, side = "left", 4, pad = "0"),
group = as.character(group))
exp_temp %>% filter(group_name == "Check name")exp_temp <- anti_join(exp_temp, transfers_long)
ff_exp <- exp_temp %>%
group_by(fy, group) %>%
summarize(sum_expenditures = round(sum(expenditure, na.rm=TRUE)/1000000 )) %>%
pivot_wider(names_from = "group", values_from = "sum_expenditures", names_prefix = "exp_")%>%
left_join(debt_keep_yearly) %>%
mutate(exp_903 = debt_cost) %>%
left_join(transfers) %>%
mutate(exp_970 = exp_971 + exp_972 + exp_975 + exp_976)
ff_exp<- ff_exp %>% select(-c(debt_cost, exp_971:exp_976)) # drop unwanted columns
exp_long <- pivot_longer(ff_exp, exp_402:exp_970 , names_to = c("type", "Category"), values_to = "Dollars", names_sep = "_") %>%
rename(Year = fy ) %>%
mutate(Category_name =
case_when(
Category == "402" ~ "AGING" ,
Category == "406" ~ "AGRICULTURE",
Category == "416" ~ "CENTRAL MANAGEMENT",
Category == "418" ~ "CHILDREN AND FAMILY SERVICES",
Category == "420" ~ "COMMERCE AND ECONOMIC OPPORTUNITY",
Category == "422" ~ "NATURAL RESOURCES" ,
Category == "426" ~ "CORRECTIONS",
Category == "427" ~ "EMPLOYMENT SECURITY" ,
Category == "444" ~ "HUMAN SERVICES" ,
Category == "448" ~ "Innovation and Technology", # AWM added fy2022
Category == "478" ~ "HEALTHCARE & FAM SER NET OF MEDICAID",
Category == "482" ~ "PUBLIC HEALTH",
Category == "492" ~ "REVENUE",
Category == "494" ~ "TRANSPORTATION" ,
Category == "532" ~ "ENVIRONMENTAL PROTECT AGENCY" ,
Category == "557" ~ "IL STATE TOLL HIGHWAY AUTH" ,
Category == "684" ~ "IL COMMUNITY COLLEGE BOARD",
Category == "691" ~ "IL STUDENT ASSISTANCE COMM" ,
Category == "900" ~ "NOT IN FRAME",
Category == "901" ~ "STATE PENSION CONTRIBUTION",
Category == "903" ~ "DEBT SERVICE",
Category == "904" ~ "State Employee Healthcare",
Category == "910" ~ "LEGISLATIVE" ,
Category == "920" ~ "JUDICIAL" ,
Category == "930" ~ "ELECTED OFFICERS" ,
Category == "940" ~ "OTHER HEALTH-RELATED",
Category == "941" ~ "PUBLIC SAFETY" ,
Category == "942" ~ "ECON DEVT & INFRASTRUCTURE" ,
Category == "943" ~ "CENTRAL SERVICES",
Category == "944" ~ "BUS & PROFESSION REGULATION" ,
Category == "945" ~ "MEDICAID" ,
Category == "946" ~ "CAPITAL IMPROVEMENT" ,
Category == "948" ~ "OTHER DEPARTMENTS" ,
Category == "949" ~ "OTHER BOARDS & COMMISSIONS" ,
Category == "959" ~ "K-12 EDUCATION" ,
Category == "960" ~ "UNIVERSITY EDUCATION",
Category == "970" ~ "Local Govt Transfers",
T ~ "CHECK ME!")
) %>%
mutate(Category_name = str_to_title(Category_name))
#exp_long_nototals <- exp_long %>% filter(Category_name != "Totals")
aggregated_totals_long <- rbind(rev_long, exp_long)
year_totals <- aggregated_totals_long %>%
group_by(type, Year) %>%
summarize(Dollars = sum(Dollars, na.rm = TRUE)) %>%
pivot_wider(names_from = "type", values_from = Dollars) %>%
rename(Expenditures = exp,
Revenue = rev) %>%
mutate(`Fiscal Gap` = Revenue - Expenditures)
# %>% arrange(desc(Year))
# creates variable for the Gap each year
year_totals %>%
mutate_all(., ~round(., digits = 0)) %>%
kbl(caption = "Fiscal Gap for each Fiscal Year ($ Millions)") %>%
kable_styling(bootstrap_options = c("striped")) %>%
kable_classic() %>%
add_footnote(c("Values include State CURE dollars (SLFRF)"))| Year | Expenditures | Revenue | Fiscal Gap |
|---|---|---|---|
| 1998 | 31243 | 32029 | 786 |
| 1999 | 33844 | 33966 | 122 |
| 2000 | 37342 | 37049 | -293 |
| 2001 | 40358 | 38289 | -2069 |
| 2002 | 42067 | 37923 | -4144 |
| 2003 | 42616 | 38452 | -4164 |
| 2004 | 53025 | 42612 | -10413 |
| 2005 | 45362 | 44305 | -1057 |
| 2006 | 48062 | 46168 | -1894 |
| 2007 | 51130 | 49493 | -1637 |
| 2008 | 54173 | 51645 | -2528 |
| 2009 | 56751 | 51467 | -5284 |
| 2010 | 59271 | 51197 | -8074 |
| 2011 | 60425 | 56303 | -4122 |
| 2012 | 59865 | 58423 | -1442 |
| 2013 | 63288 | 63102 | -186 |
| 2014 | 66963 | 65266 | -1697 |
| 2015 | 69940 | 66586 | -3354 |
| 2016 | 63935 | 64157 | 222 |
| 2017 | 71727 | 63659 | -8068 |
| 2018 | 74972 | 73016 | -1956 |
| 2019 | 74406 | 74638 | 232 |
| 2020 | 82250 | 80590 | -1660 |
| 2021 | 93630 | 95207 | 1577 |
| 2022 | 100884 | 116059 | 15175 |
| 2023 | 112863 | 111772 | -1091 |
| a Values include State CURE dollars (SLFRF) |
# does not include rev_type == 58, medicaid dollars
covid_dollars_rev <- rev_temp %>% filter(covid_dollars==1) # check what was dropped
covid_dollars_rev %>% group_by(fy, agency_name) %>%
summarize(receipts = sum(receipts)) %>%
pivot_wider(names_from="agency_name", values_from = "receipts") %>% arrange(-fy)covid_dollars_rev %>% group_by(fy, fund_name_ab) %>%
summarize(receipts = sum(receipts)) %>%
arrange(-fy) %>%
pivot_wider(names_from="fy", values_from = "receipts")K12_ESSER_words <- c("CRRSA","ESSER","EMER R", "EMR R", "CARES", "AMER R", "EMER ED")
ESSER_exp <- exp_temp %>%
filter(agency_name == "STATE BOARD OF EDUCATION") %>%
mutate(ESSERfunds = case_when(
str_detect(wh_approp_name, "CRRSA") ~ "ESSER",
str_detect(wh_approp_name, "ESSER") ~ "ESSER",
str_detect(wh_approp_name, "EMER R") ~ "ESSER",
str_detect(wh_approp_name, "EMR R") ~ "ESSER",
str_detect(wh_approp_name, "CARES") ~ "ESSER",
str_detect(wh_approp_name, "AMER R") ~ "ESSER",
str_detect(wh_approp_name, "EMER ED") ~ "ESSER",
TRUE ~ 'not_esser')) %>%
filter(ESSERfunds == "ESSER")
ESSER_exp#dropped_inff_0 <- exp_temp %>% filter(in_ff == 0)
#exp_temp <- exp_temp %>% filter(in_ff == 1) # drops in_ff = 0 funds AFTER dealing with net-revenue aboverev_temp <- rev_temp %>% filter(covid_dollars==0) # keeps observations that were not coded as COVID federal funds
ff_rev <- rev_temp %>%
mutate(rev_type_new = str_pad(rev_type_new, 2, "left", pad = "0")) %>%
group_by(rev_type_new, fy) %>%
summarize(sum_receipts = round(sum(receipts, na.rm=TRUE)/1000000 )) %>%
pivot_wider(names_from = "rev_type_new", values_from = "sum_receipts", names_prefix = "rev_")
# ff_rev<- left_join(ff_rev, tax_refund)
ff_rev <- mutate_all(ff_rev, ~replace_na(.,0))
#
# ff_rev <- ff_rev %>%
# select(-c(# ref_02:ref_35,
# ref_CHECK
# ))
rev_long <- pivot_longer(ff_rev, rev_02:rev_78, names_to = c("type","Category"), values_to = "Dollars", names_sep = "_") %>%
rename(Year = fy) %>%
mutate(Category_name = case_when(
Category == "02" ~ "INDIVIDUAL INCOME TAX" ,
Category == "03" ~ "CORPORATE INCOME TAX" ,
Category == "06" ~ "SALES TAX" ,
Category == "09" ~ "MOTOR FUEL TAX" ,
Category == "12" ~ "PUBLIC UTILITY TAX" ,
Category == "15" ~ "CIGARETTE TAXES" ,
Category == "18" ~ "LIQUOR GALLONAGE TAXES" ,
Category == "21" ~ "INHERITANCE TAX" ,
Category == "24" ~ "INSURANCE TAXES&FEES&LICENSES" ,
Category == "27" ~ "CORP FRANCHISE TAXES & FEES" ,
Category == "30" ~ "HORSE RACING TAXES & FEES", # in Other
Category == "31" ~ "MEDICAL PROVIDER ASSESSMENTS" ,
Category == "32" ~ "GARNISHMENT-LEVIES" , # dropped
Category == "33" ~ "LOTTERY RECEIPTS" ,
Category == "35" ~ "OTHER TAXES" ,
Category == "36" ~ "RECEIPTS FROM REVENUE PRODUCING",
Category == "39" ~ "LICENSES, FEES & REGISTRATIONS" ,
Category == "42" ~ "MOTOR VEHICLE AND OPERATORS" ,
Category == "45" ~ "STUDENT FEES-UNIVERSITIES", # dropped
Category == "48" ~ "RIVERBOAT WAGERING TAXES" ,
Category == "51" ~ "RETIREMENT CONTRIBUTIONS" , # dropped
Category == "54" ~ "GIFTS AND BEQUESTS",
Category == "57" ~ "FEDERAL OTHER" ,
Category == "58" ~ "FEDERAL MEDICAID",
Category == "59" ~ "FEDERAL TRANSPORTATION" ,
Category == "60" ~ "OTHER GRANTS AND CONTRACTS", #other
Category == "63" ~ "INVESTMENT INCOME", # other
Category == "66" ~ "PROCEEDS,INVESTMENT MATURITIES" , #dropped
Category == "72" ~ "BOND ISSUE PROCEEDS", #dropped
Category == "75" ~ "INTER-AGENCY RECEIPTS ", #dropped
Category == "76" ~ "TRANSFER IN FROM OUT FUNDS", #other
Category == "78" ~ "ALL OTHER SOURCES" ,
Category == "79" ~ "COOK COUNTY IGT", #dropped
Category == "98" ~ "PRIOR YEAR REFUNDS", #dropped
T ~ "Check Me!"
) )%>%
mutate(Category_name = str_to_title(Category_name))exp_temp <- exp_temp %>% filter(in_ff == 1) # drops in_ff = 0 funds AFTER dealing with net-revenue above
exp_temp <- exp_temp %>%
#mutate(agency = as.numeric(agency) ) %>%
# arrange(agency)%>%
mutate(
group = case_when(
agency>"100"& agency<"200" ~ "910", # legislative
agency == "528" | (agency>"200" & agency<"300") ~ "920", # judicial
pension>0 ~ "901", # pensions
(agency>"309" & agency<"400") ~ "930", # elected officers
agency == "586" ~ "959", # create new K-12 group
agency=="402" | agency=="418" | agency=="478" | agency=="444" | agency=="482" ~ as.character(agency), # aging, Children and Family Services (DCFS), Healthcare and Family Services (DHFS), human services (DHS), public health (DPH)
T ~ as.character(group))
) %>%
mutate(group = case_when(
agency=="478" & (appr_org=="01" | appr_org == "65" | appr_org=="88") & (object=="4900" | object=="4400") ~ "945", # separates CHIP from health and human services and saves it as Medicaid
agency == "586" & fund == "0355" ~ "945", # 586 (Board of Edu) has special education which is part of medicaid
# OLD CODE: agency == "586" & appr_org == "18" ~ "945", # Spec. Edu Medicaid Matching
agency=="425" | agency=="466" | agency=="546" | agency=="569" | agency=="578" | agency=="583" | agency=="591" | agency=="592" | agency=="493" | agency=="588" ~ "941", # public safety & Corrections
agency=="406" | agency=="420" | agency=="494" | agency=="557" ~ as.character(agency), # econ devt & infra, tollway
agency=="511" | agency=="554" | agency=="574" | agency=="598" ~ "946", # Capital improvement
agency=="422" | agency=="532" ~ as.character(agency), # environment & nat. resources
agency=="440" | agency=="446" | agency=="524" | agency=="563" ~ "944", # business regulation
agency=="492" ~ "492", # revenue
agency == "416" ~ "416", # central management services
agency=="448" & fy > 2016 ~ "416", #add DoIT to central management
T ~ as.character(group))) %>%
mutate(group = case_when(
# agency=="684" | agency=="691" ~ as.character(agency), # moved under higher education in next line. 11/28/2022 AWM
agency=="692" | agency=="695" | agency == "684" |agency == "691" | (agency>"599" & agency<"677") ~ "960", # higher education
agency=="427" ~ as.character(agency), # employment security
agency=="507"| agency=="442" | agency=="445" | agency=="452" |agency=="458" | agency=="497" ~ "948", # other departments
# other boards & Commissions
agency=="503" | agency=="509" | agency=="510" | agency=="565" |agency=="517" | agency=="525" | agency=="526" | agency=="529" | agency=="537" | agency=="541" | agency=="542" | agency=="548" | agency=="555" | agency=="558" | agency=="559" | agency=="562" | agency=="564" | agency=="568" | agency=="579" | agency=="580" | agency=="587" | agency=="590" | agency=="527" | agency=="585" | agency=="567" | agency=="571" | agency=="575" | agency=="540" | agency=="576" | agency=="564" | agency=="534" | agency=="520" | agency=="506" | agency == "533" ~ "949",
# non-pension expenditures of retirement funds moved to "Other Departments"
# should have removed pension expenditures already from exp_temp in Pensions step above
agency=="131" | agency=="275" | agency=="589" |agency=="593"|agency=="594"|agency=="693" ~ "948",
T ~ as.character(group))) %>%
mutate(group_name =
case_when(
group == "416" ~ "Central Management",
group == "478" ~ "Healthcare and Family Services",
group == "482" ~ "Public Health",
group == "900" ~ "NOT IN FRAME",
group == "901" ~ "STATE PENSION CONTRIBUTION",
group == "903" ~ "DEBT SERVICE",
group == "910" ~ "LEGISLATIVE" ,
group == "920" ~ "JUDICIAL" ,
group == "930" ~ "ELECTED OFFICERS" ,
group == "940" ~ "OTHER HEALTH-RELATED",
group == "941" ~ "PUBLIC SAFETY" ,
group == "942" ~ "ECON DEVT & INFRASTRUCTURE" ,
group == "943" ~ "CENTRAL SERVICES",
group == "944" ~ "BUS & PROFESSION REGULATION" ,
group == "945" ~ "MEDICAID" ,
group == "946" ~ "CAPITAL IMPROVEMENT" ,
group == "948" ~ "OTHER DEPARTMENTS" ,
group == "949" ~ "OTHER BOARDS & COMMISSIONS" ,
group == "959" ~ "K-12 EDUCATION" ,
group == "960" ~ "UNIVERSITY EDUCATION" ,
group == agency ~ as.character(group),
TRUE ~ "Check name"),
year = fy)exp_temp <- read_csv("data/all_expenditures_recoded.csv") %>%
#exp_temp <- read.csv("data/exp_fy23_recoded_02April2024.csv") %>%
#exp_temp <- read.csv("data/exp_temp.csv") %>%
mutate(agency = as.character(agency),
object = as.character(object),
object = str_pad(object, side = "left", 4, pad = "0"),
sequence = as.character(sequence),
sequence = str_pad(sequence, side = "left", 2, pad = "0"),
type = as.character(type),
type = str_pad(type, side = "left", 2, pad = "0"),
appr_org = as.character(appr_org),
appr_org = str_pad(appr_org, side = "left", 2, pad = "0"),
fund = as.character(fund),
fund = str_pad(fund, side = "left", 4, pad = "0"))
ff_exp <- exp_temp %>%
group_by(fy, group) %>%
summarize(sum_expenditures = round(sum(expenditure, na.rm=TRUE)/1000000 )) %>%
pivot_wider(names_from = "group", values_from = "sum_expenditures", names_prefix = "exp_")%>%
left_join(debt_keep_yearly) %>%
mutate(exp_903 = debt_cost) %>%
left_join(transfers) %>%
mutate(exp_970 = exp_971 + exp_972 + exp_975 + exp_976)
#ff_exp<- ff_exp %>% select(-c(debt_cost, exp_971:exp_976)) # drop unwanted columns
exp_long <- pivot_longer(ff_exp, exp_402:exp_970 , names_to = c("type", "Category"), values_to = "Dollars", names_sep = "_") %>%
rename(Year = fy ) %>%
mutate(Category_name =
case_when(
Category == "402" ~ "AGING" ,
Category == "406" ~ "AGRICULTURE",
Category == "416" ~ "CENTRAL MANAGEMENT",
Category == "418" ~ "CHILDREN AND FAMILY SERVICES",
Category == "420" ~ "COMMERCE AND ECONOMIC OPPORTUNITY",
Category == "422" ~ "NATURAL RESOURCES" ,
Category == "426" ~ "CORRECTIONS",
Category == "427" ~ "EMPLOYMENT SECURITY" ,
Category == "444" ~ "HUMAN SERVICES" ,
Category == "448" ~ "Innovation and Technology", # AWM added fy2022
Category == "478" ~ "HEALTHCARE & FAM SER NET OF MEDICAID",
Category == "482" ~ "PUBLIC HEALTH",
Category == "492" ~ "REVENUE",
Category == "494" ~ "TRANSPORTATION" ,
Category == "532" ~ "ENVIRONMENTAL PROTECT AGENCY" ,
Category == "557" ~ "IL STATE TOLL HIGHWAY AUTH" ,
Category == "684" ~ "IL COMMUNITY COLLEGE BOARD",
Category == "691" ~ "IL STUDENT ASSISTANCE COMM" ,
Category == "900" ~ "NOT IN FRAME",
Category == "901" ~ "STATE PENSION CONTRIBUTION",
Category == "903" ~ "DEBT SERVICE",
Category == "904" ~ "State Employee Healthcare",
Category == "910" ~ "LEGISLATIVE" ,
Category == "920" ~ "JUDICIAL" ,
Category == "930" ~ "ELECTED OFFICERS" ,
Category == "940" ~ "OTHER HEALTH-RELATED",
Category == "941" ~ "PUBLIC SAFETY" ,
Category == "942" ~ "ECON DEVT & INFRASTRUCTURE" ,
Category == "943" ~ "CENTRAL SERVICES",
Category == "944" ~ "BUS & PROFESSION REGULATION" ,
Category == "945" ~ "MEDICAID" ,
Category == "946" ~ "CAPITAL IMPROVEMENT" ,
Category == "948" ~ "OTHER DEPARTMENTS" ,
Category == "949" ~ "OTHER BOARDS & COMMISSIONS" ,
Category == "959" ~ "K-12 EDUCATION" ,
Category == "960" ~ "UNIVERSITY EDUCATION",
Category == "970" ~ "Local Govt Transfers",
T ~ "CHECK ME!")
) %>%
mutate(Category_name = str_to_title(Category_name))
#exp_long_nototals <- exp_long %>% filter(Category_name != "Totals")
aggregated_totals_long <- rbind(rev_long, exp_long) Change plots:
year_totals2 <- aggregated_totals_long %>%
group_by(type, Year) %>%
summarize(Dollars = sum(Dollars, na.rm = TRUE)) %>%
pivot_wider(names_from = "type", values_from = Dollars) %>%
rename(
Expenditures = exp,
Revenue = rev) %>%
mutate(`Fiscal Gap` = round(Revenue - Expenditures)) %>%
arrange(desc(Year))
# creates variable for the Gap each year
year_totals2 # gap for FY22 changed to 2.3 billionannotation_billions <- data.frame(
x = c(2004, 2017, 2019),
y = c(60, 50, 10),
label = c("Expenditures","Revenue", "Fiscal Gap"))
fiscal_gap1 <- year_totals %>%
ggplot() +
geom_hline(yintercept = 0) +
geom_line(aes(x = Year, y = Revenue/1000), color = "Black", lwd=1) +
geom_line(aes(x = Year, y = Expenditures/1000, linetype = "dashed"), color = "red", lwd=1) +
geom_line(aes(x = Year, y = `Fiscal Gap`/1000), color = "gray") +
geom_text(data = annotation_billions, aes(x=x, y=y, label=label))+
theme_classic() +
theme(legend.position = "none", #axis.text.y = element_blank(),
#axis.ticks.y = element_blank(),
axis.title.y = element_blank())+
scale_linetype_manual(values = c("dashed", "dashed")) +
scale_y_continuous(limits = c(-20, 120), labels = comma)+
scale_x_continuous(limits=c(1998,2023), expand = c(0,0))
fiscal_gap1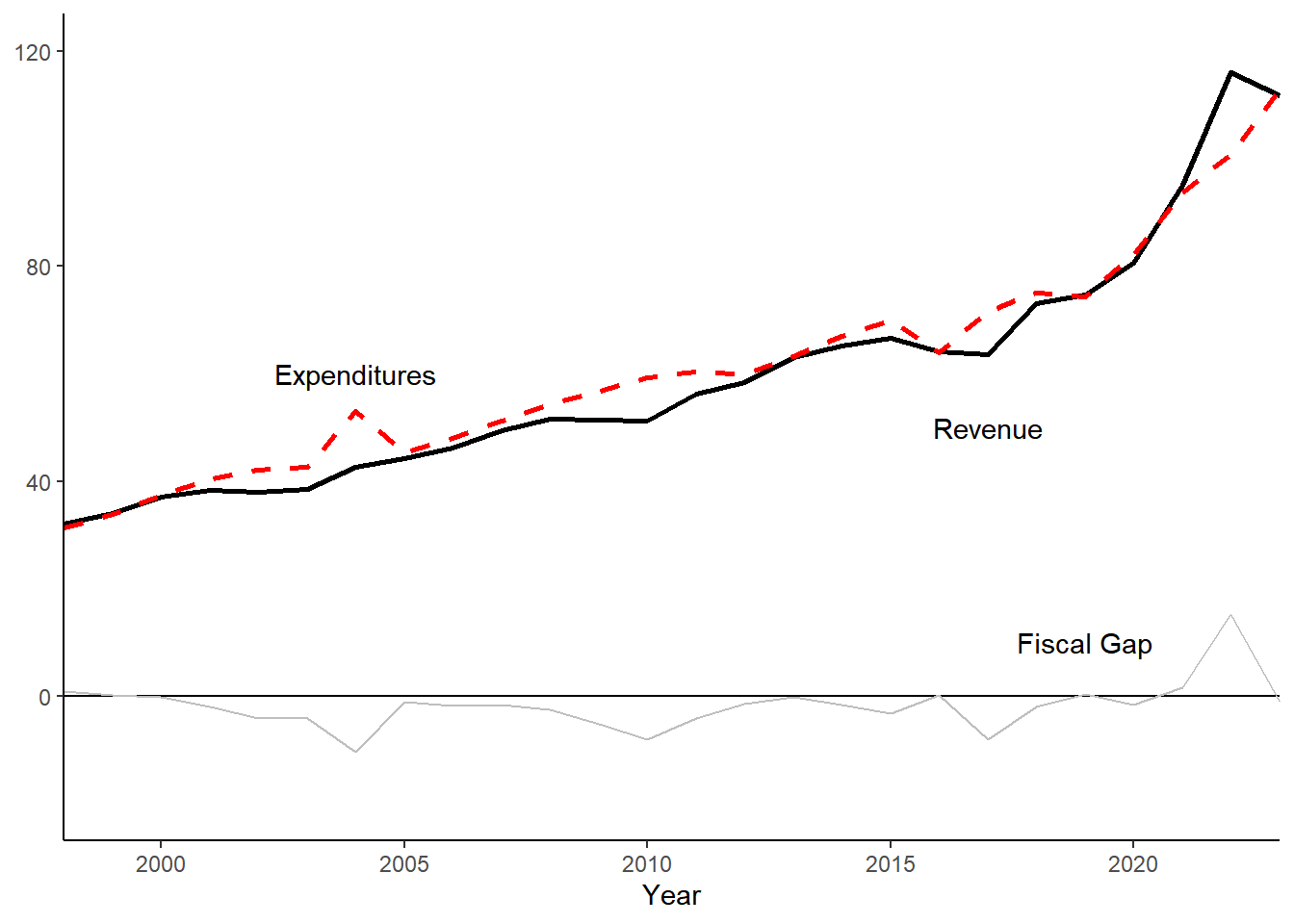
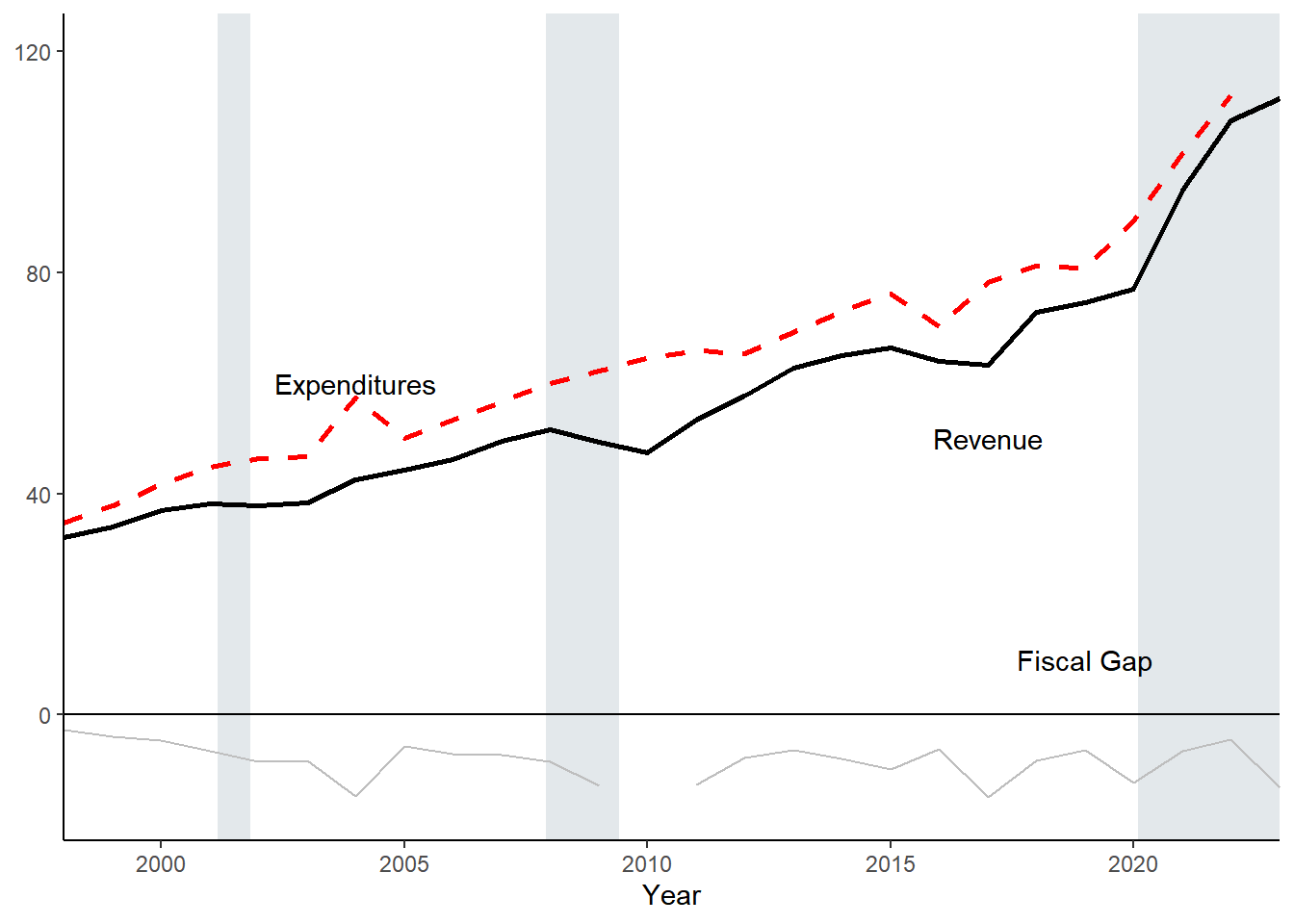
fiscal_gap_droppedCURE <- year_totals2 %>%
ggplot() +
geom_hline(yintercept = 0) +
geom_line(aes(x = Year, y = Revenue/1000), color = "Black", lwd=1) +
geom_line(aes(x = Year, y = Expenditures/1000, linetype = "dashed"), color = "red", lwd=1) +
geom_line(aes(x = Year, y = `Fiscal Gap`/1000), color = "gray") +
geom_text(data = annotation_billions, aes(x=x, y=y, label=label))+
theme_classic() +
theme(legend.position = "none",# axis.text.y = element_blank(),
#axis.ticks.y = element_blank(),
axis.title.y = element_blank() )+
scale_linetype_manual(values = c("dashed", "dashed")) +
scale_y_continuous(limits=c(-20,120), labels = comma)+
scale_x_continuous(limits=c(1998, 2023), expand = c(0,0))
# # geom_smooth adds regression line, graphed first so it appears behind line graph
# geom_smooth(aes(x = Year, y = Revenue), color = "gray", method = "lm", se = FALSE) +
# geom_smooth(aes(x = Year, y = Expenditures), color = "rosybrown2", method = "lm", se = FALSE) +
#
# # line graph of revenue and expenditures
# geom_line(aes(x = Year, y = Revenue), color = "black", size=1) +
# geom_line(aes(x = Year, y = Expenditures), color = "red", size=1) +
# geom_line(aes(x=Year, y = `Fiscal Gap`), color="gray") +
#
# geom_text(data= annotation, aes(x=x, y = y, label=label))+
#
# # labels
# theme_bw() +
# scale_y_continuous(labels = comma)+
# xlab("Year") +
# ylab("Millions of Dollars") +
# ggtitle("Illinois Expenditures and Revenue Totals, 1998-2022")
fiscal_gap_droppedCURE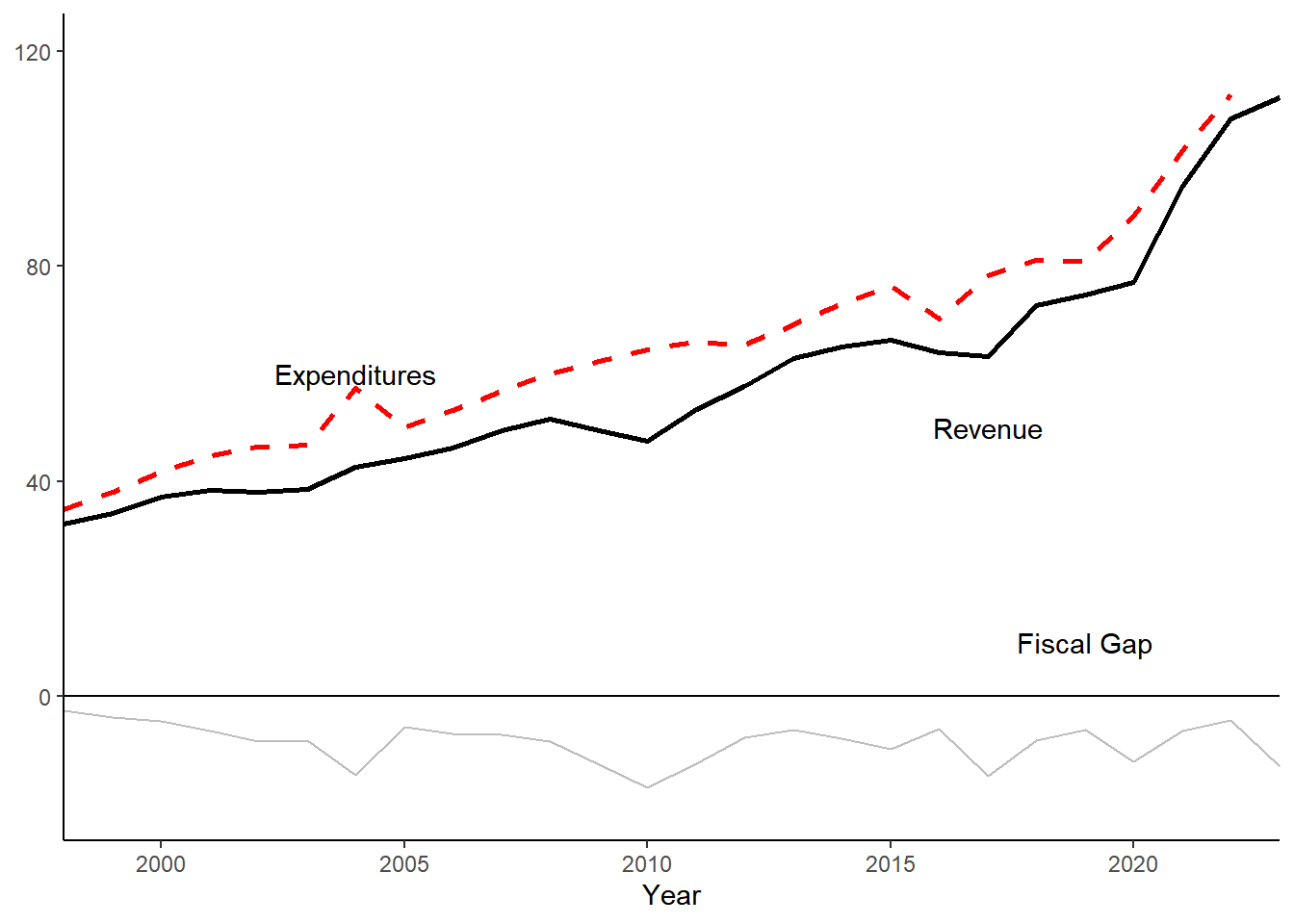
Compare with and without federal COVID dollars:
library(gridExtra)
cowplot::plot_grid(fiscal_gap1,
fiscal_gap_droppedCURE, nrow=1,
labels = c("With ARPA State CURE Funds", "Without ARPA State Cure Funds"))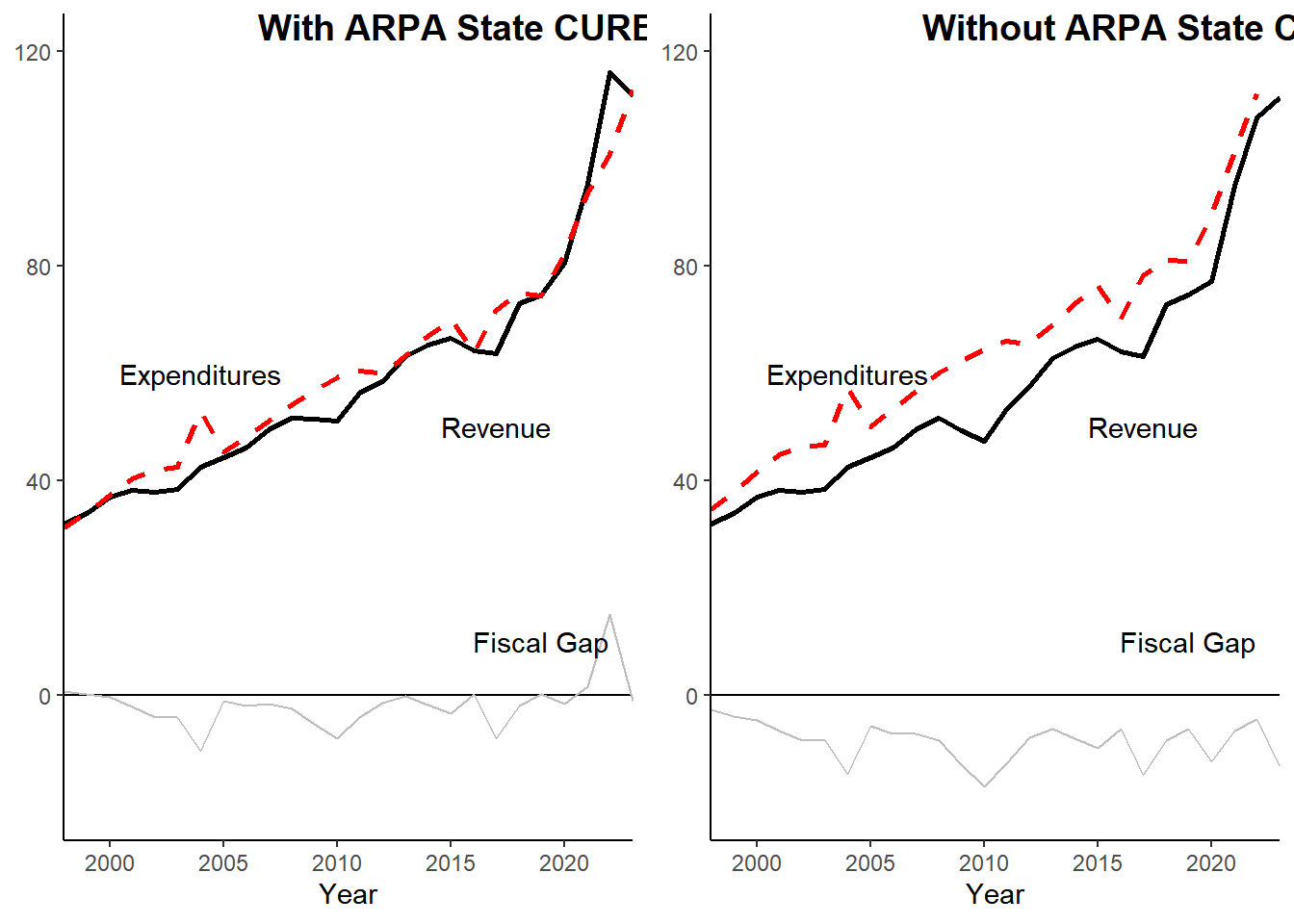
Revenue amounts in millions of dollars:
rev_long %>%
filter(Year == 2023) %>%
#mutate(`Total Expenditures`= sum(Dollars, na.rm = TRUE)) %>%
# select(-c(Year, `Total Expenditures`)) %>%
arrange(desc(`Dollars`)) %>%
ggplot() +
geom_col(aes(x = fct_reorder(Category_name, `Dollars`), y = `Dollars`))+
coord_flip() +
theme_bw() +
labs(title = "Revenues for FY2023")+
xlab("Revenue Categories") +
ylab("Millions of Dollars")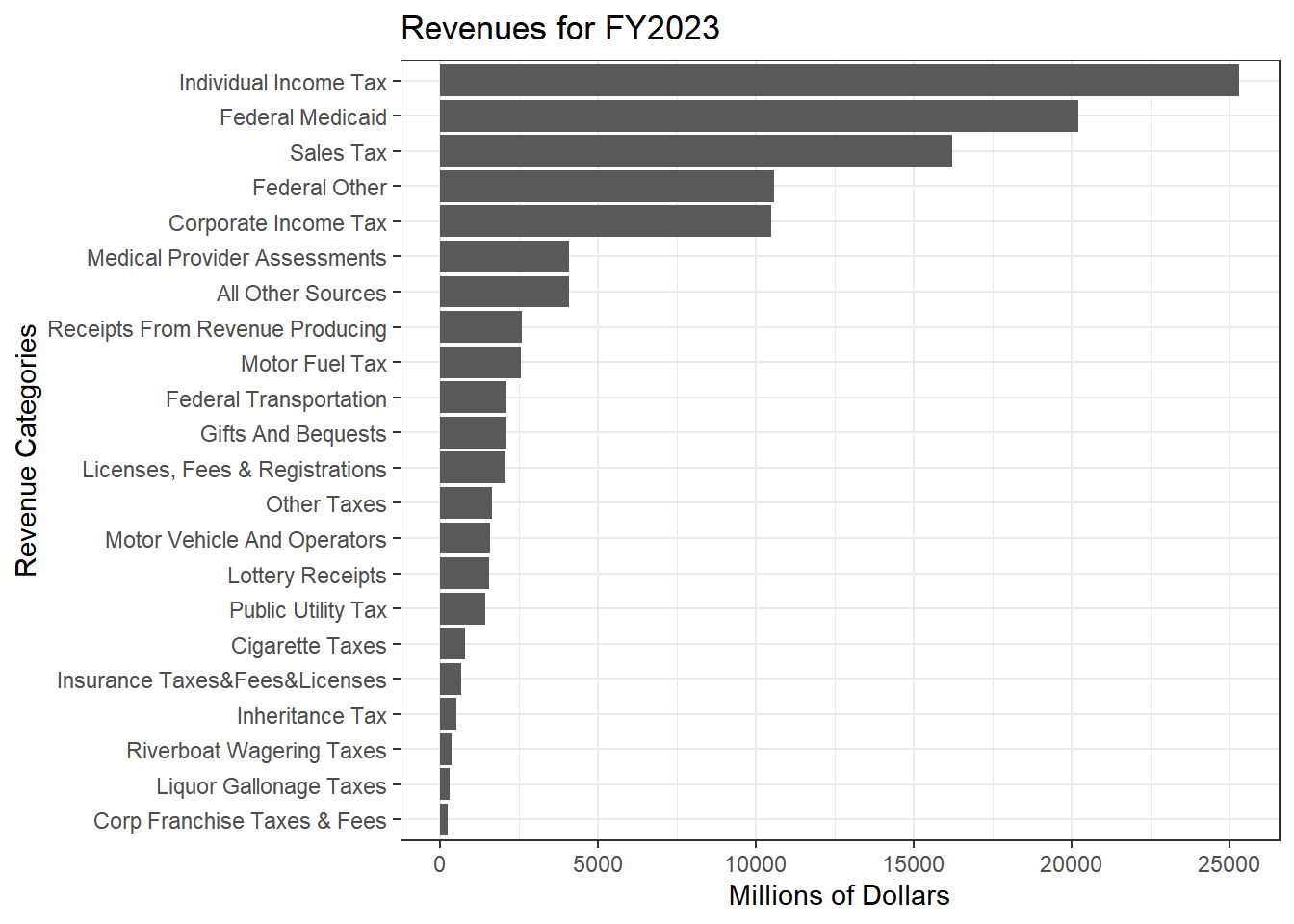
First images use revenue that includes all federal stimulus packages. Revenue projections are skewed heavily due to the large amount of covid money flowing in the past 2 years.
## Revenues
year_totals2 <- year_totals2 %>%
arrange(Year)
#ts_rev <- year_totals %>% select(Year, Revenue ) %>% arrange(Year)
tsrev <- ts(year_totals2$Revenue, start ="1998", frequency = 1) # yearly data
# start(tsrev) # 1998, January
# end(tsrev) ## 2022
# summary(tsrev)
# plot(tsrev)
# abline(reg=lm(tsrev~time(tsrev)))
#### ARIMAs
mymodel <- auto.arima(tsrev, seasonal = FALSE)
# mymodel # ARIMA (0, 1, 0) with drift
myforecastrev <- forecast(mymodel, h = 20)
#plot(myforecastrev, xlab ="", ylab ="Total Revenue", main ="Chicago Revenue")
#### revenue chart
model_rev <- auto.arima(tsrev, seasonal = FALSE)
forecast_rev <- forecast(model_rev, h = 20)
q <- forecast(forecast_rev, h = 20) %>%
autoplot() +
ylab("Dollars (Millions)") +
xlab("Year") +
ggtitle("Forecasted Revenue") +
theme_classic() +
scale_y_continuous(labels = dollar )
summary(forecast_rev)
Forecast method: ARIMA(0,1,1) with drift
Model Information:
Series: tsrev
ARIMA(0,1,1) with drift
Coefficients:
ma1 drift
0.8419 3148.990
s.e. 0.1666 1346.163
sigma^2 = 15033493: log likelihood = -241.62
AIC=489.24 AICc=490.38 BIC=492.9
Error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set 36.283 3646.76 2655.534 -0.5337082 4.391722 0.6999963 -0.1585794
Forecasts:
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
2024 115441.6 110472.6 120410.7 107842.10 123041.1
2025 118590.6 108176.3 129004.9 102663.30 134517.9
2026 121739.6 107875.1 135604.1 100535.69 142943.5
2027 124888.6 108275.6 141501.6 99481.26 150295.9
2028 128037.6 109070.3 147004.8 99029.67 157045.5
2029 131186.6 110126.6 152246.6 98978.10 163395.0
2030 134335.6 111372.8 157298.3 99217.02 169454.1
2031 137484.6 112765.0 162204.1 99679.28 175289.8
2032 140633.5 114274.1 166993.0 100320.20 180946.9
2033 143782.5 115879.3 171685.7 101108.28 186456.8
2034 146931.5 117565.6 176297.4 102020.29 191842.7
2035 150080.5 119321.4 180839.6 103038.56 197122.5
2036 153229.5 121137.6 185321.4 104149.24 202309.8
2037 156378.5 123007.0 189749.9 105341.27 207415.7
2038 159527.5 124923.7 194131.2 106605.61 212449.4
2039 162676.5 126882.8 198470.1 107934.79 217418.1
2040 165825.5 128880.2 202770.7 109322.56 222328.4
2041 168974.4 130912.4 207036.5 110763.59 227185.3
2042 172123.4 132976.5 211270.4 112253.32 231993.6
2043 175272.4 135069.8 215475.1 113787.82 236757.0# annotation <- data.frame(
# x = c(2027, 2032),
# y = c(200000, 300000),
# label = c("$120 billion in 2027","$135 billion in 2032")
# )
annotation <- data.frame(
x = c(2020, 2032),
y = c(150000, 200000),
label = c("$125 billion in 2027","$141 billion in 2032")
)
q+ geom_label(data = annotation, aes(x=x, y=y, label=label), size = 3) +
labs(caption = "after dropping federal covid dollars")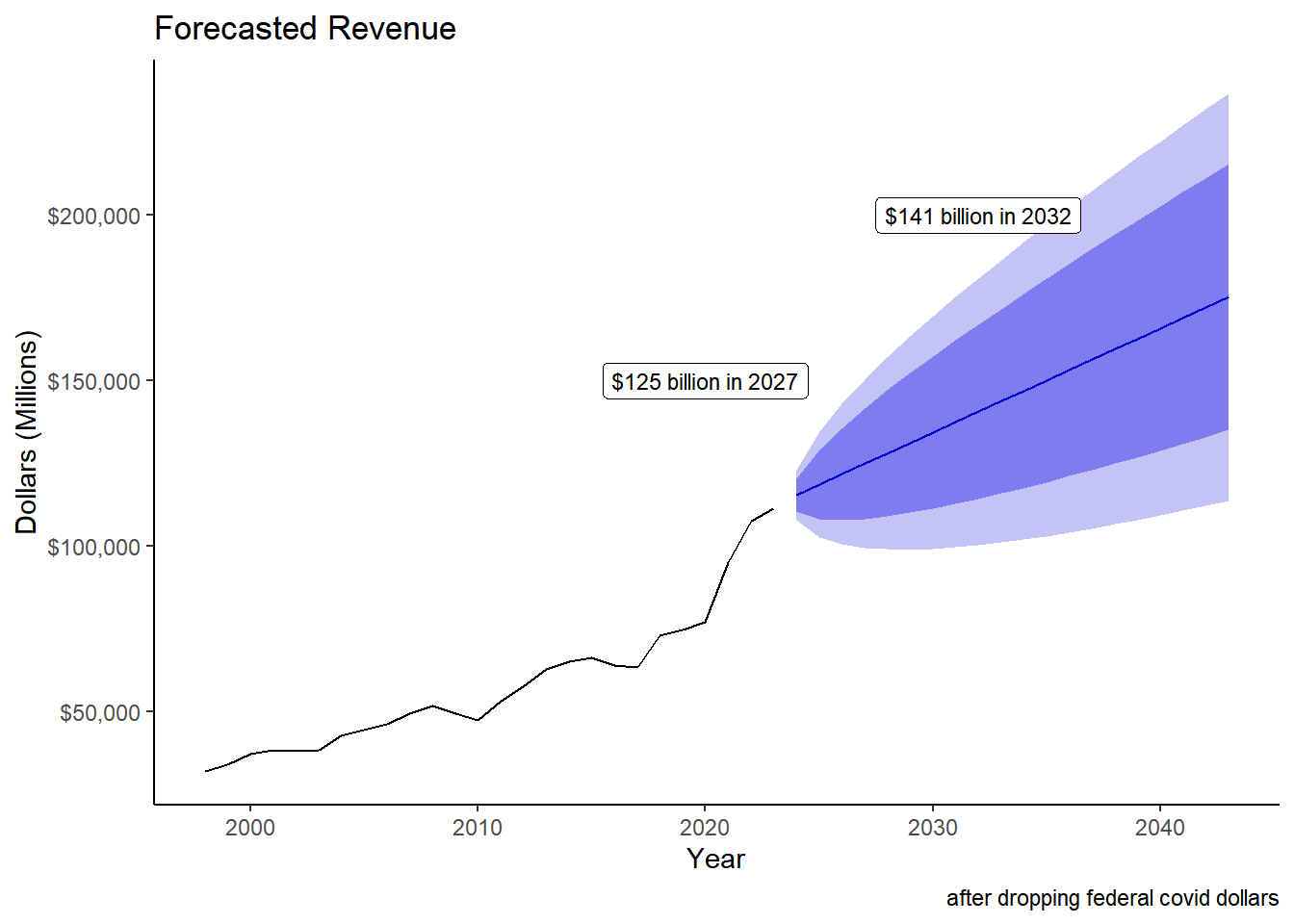
## Expenditures
tsexp <- ts(year_totals2$Expenditures, start = "1998", frequency = 1)
model_exp<- auto.arima(tsexp, seasonal = FALSE)
# model_exp # ARIMA (0,1,1) with drift
forecast_exp <- forecast(model_exp, h = 20)
#plot(forecast_exp, xlab ="", ylab ="Total Expenditures", main ="Chicago Expenditures")
p <- forecast(model_exp, h = 20) %>%
autoplot() +
ylab("Dollars (Millions)") +
xlab("Year") +
ggtitle("Forecasted Expenditures") +
theme_classic() +
scale_y_continuous(labels = dollar )
summary(forecast_exp)
Forecast method: ARIMA(0,1,0) with drift
Model Information:
Series: tsexp
ARIMA(0,1,0) with drift
Coefficients:
drift
3597.3827
s.e. 947.0728
sigma^2 = 23357929: log likelihood = -247.04
AIC=498.09 AICc=498.63 BIC=500.53
Error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set 1.197003 4643.4 3178.97 -0.9251133 4.479552 0.6733181 0.05745899
Forecasts:
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
2024 128251.4 122057.7 134445.2 118778.9 137723.9
2025 131848.8 123089.5 140608.1 118452.7 145245.0
2026 135446.2 124718.3 146174.1 119039.3 151853.1
2027 139043.6 126656.1 151431.1 120098.5 157988.6
2028 142641.0 128791.3 156490.6 121459.8 163822.1
2029 146238.3 131066.8 161409.9 123035.5 169441.2
2030 149835.7 133448.6 166222.8 124773.8 174897.6
2031 153433.1 135914.6 170951.7 126640.8 180225.4
2032 157030.5 138449.3 175611.7 128612.9 185448.0
2033 160627.9 141041.5 180214.2 130673.2 190582.6
2034 164225.3 143682.9 184767.6 132808.5 195642.0
2035 167822.6 146366.9 189278.4 135008.9 200636.4
2036 171420.0 149088.2 193751.9 137266.4 205573.7
2037 175017.4 151842.5 198192.3 139574.5 210460.3
2038 178614.8 154626.5 202603.1 141927.9 215301.7
2039 182212.2 157437.2 206987.1 144322.1 220102.2
2040 185809.6 160272.1 211347.0 146753.4 224865.7
2041 189406.9 163129.1 215684.8 149218.5 229595.4
2042 193004.3 166006.4 220002.2 151714.6 234294.0
2043 196601.7 168902.4 224301.0 154239.3 238964.1annotation <- data.frame(
x = c(2027, 2032),
y = c(139000, 100000), label = c("$117 ± 20 Billion in 2027","$161 ± 20 Billion in 2032 ")
)
p +
geom_label(data = annotation, aes(x=x, y=y, label=label), size = 3) +
labs(title = "Forecasted Expenditures",
caption = "Projected values at 95% confidence interval.
Dark blue represents 80% liklihood of falling with that range,
light blue represents 95% liklihood of being in projected range.")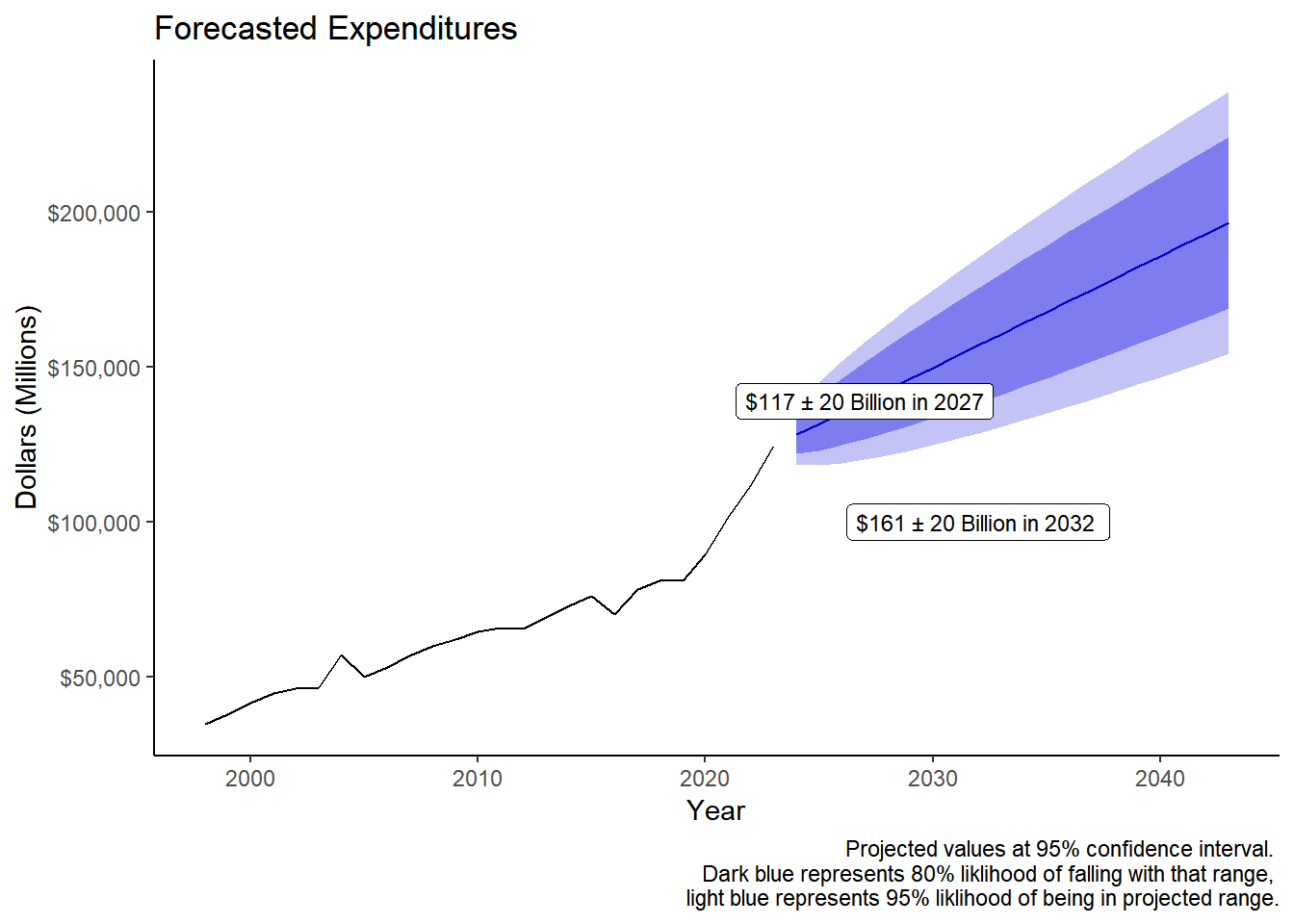
## Exp and Rev together
autoplot(tsexp) +
#geom_line(tsexp)+
#geom_line(aes(model_rev))+
autolayer(forecast_rev, series = "Revenue") +
autolayer(forecast_exp, series = "Expenditure)", alpha = 0.5) +
geom_line(year_totals, mapping= aes(x = Year, y = Revenue)) + guides(colour = guide_legend("Forecast")) +
labs(title = "Forecasted Revenue and Expenditures", caption = "Revenue includes State and Local CURE Dollars")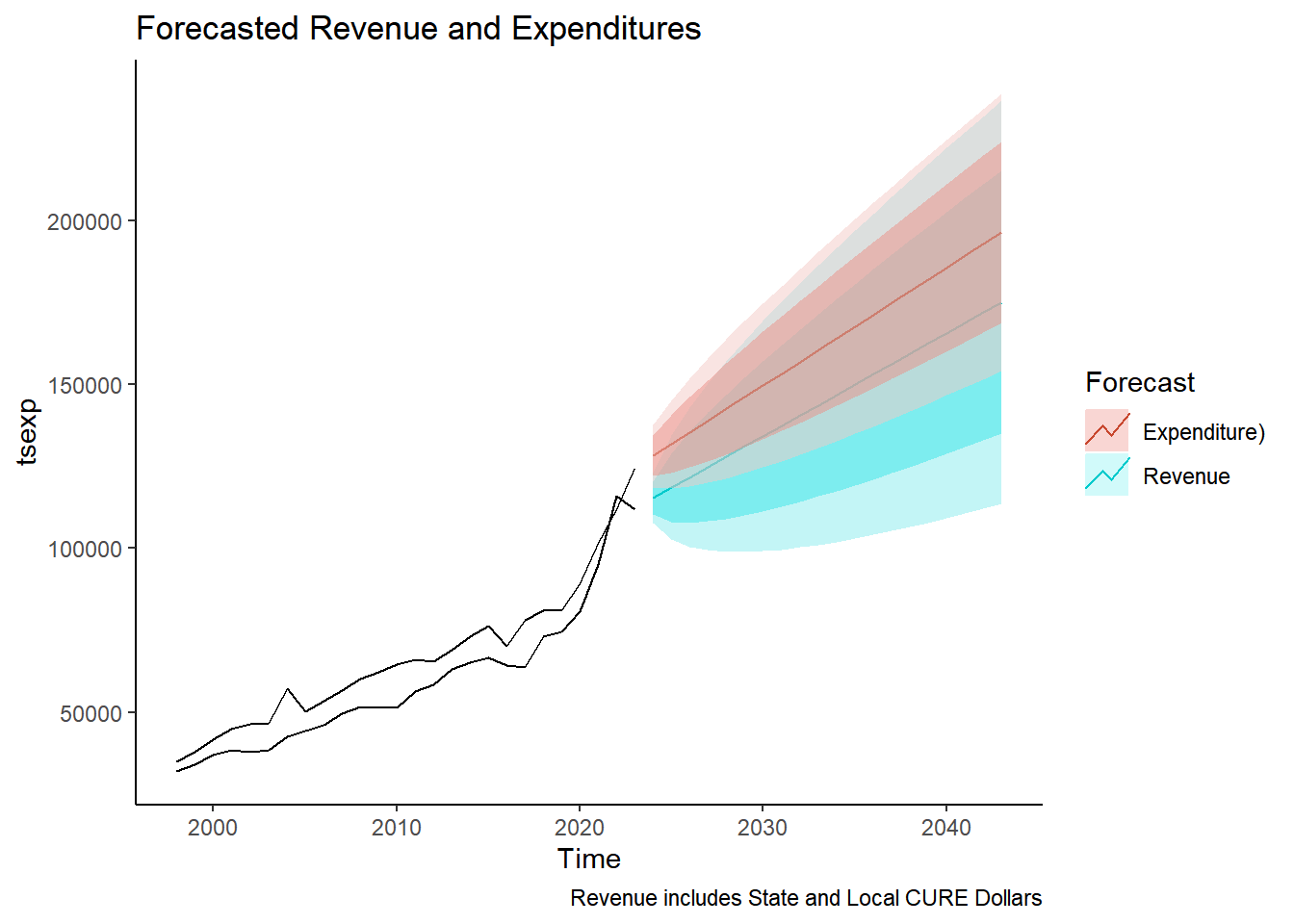
Revenue forecasting using precovid trends:
# revenue using precovid trends
tsrev <- ts(year_totals$Revenue, start ="1998", end = "2020", frequency = 1) # yearly data
tsexp2019 <- ts(year_totals$Expenditures, start ="1998", end = "2020", frequency = 1) # yearly data
#### revenue chart
model_rev <- auto.arima(tsrev, seasonal = FALSE)
forecast_rev <- forecast(model_rev, h = 23)
c <- forecast(forecast_rev, h = 22) %>%
autoplot() +
ylab("Dollars (Millions)") +
xlab("Year") +
ggtitle("Forecasted Revenue") +
theme_classic() +
scale_y_continuous(labels = dollar )
summary(forecast_rev)
Forecast method: ARIMA(0,1,0) with drift
Model Information:
Series: tsrev
ARIMA(0,1,0) with drift
Coefficients:
drift
2207.3182
s.e. 534.1556
sigma^2 = 6576007: log likelihood = -203.39
AIC=410.79 AICc=411.42 BIC=412.97
Error measures:
ME RMSE MAE MPE MAPE MASE
Training set 1.296594 2450.343 1758.755 -0.3029288 3.155213 0.6904094
ACF1
Training set -0.06929682
Forecasts:
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
2021 82797.32 79510.94 86083.69 77771.24 87823.40
2022 85004.64 80357.00 89652.27 77896.69 92112.58
2023 87211.95 81519.78 92904.12 78506.53 95917.38
2024 89419.27 82846.52 95992.02 79367.12 99471.43
2025 91626.59 84278.03 98975.15 80387.94 102865.24
2026 93833.91 85783.97 101883.85 81522.58 106145.24
2027 96041.23 87346.29 104736.16 82743.47 109338.98
2028 98248.55 88953.27 107543.82 84032.65 112464.44
2029 100455.86 90596.74 110314.99 85377.63 115534.10
2030 102663.18 92270.75 113055.61 86769.33 118557.04
2031 104870.50 93970.82 115770.18 88200.88 121540.12
2032 107077.82 95693.48 118462.16 89666.97 124488.66
2033 109285.14 97435.94 121134.33 91163.35 127406.92
2034 111492.45 99195.96 123788.95 92686.59 130298.32
2035 113699.77 100971.69 126427.85 94233.86 133165.69
2036 115907.09 102761.59 129052.59 95802.78 136011.40
2037 118114.41 104564.33 131664.48 97391.36 138837.46
2038 120321.73 106378.82 134264.64 98997.88 141645.57
2039 122529.05 108204.07 136854.03 100620.88 144437.21
2040 124736.36 110039.24 139433.48 102259.06 147213.67
2041 126943.68 111883.62 142003.75 103911.30 149976.07
2042 129151.00 113736.53 144565.47 105576.60 152725.40
2043 131358.32 115597.41 147119.22 107254.09 155462.54annotation <- data.frame(
x = c(2020, 2032),
y = c(90000, 100000),
label = c("$96 Billion in 2027","$107 Billion in 2032")
)
c+ geom_label(data = annotation, aes(x=x, y=y, label=label), size = 3) +
labs(title= "Revenue Forecasted using Pre-Covid Data",
subtitle = "Own Source and Federal Revenues Combined")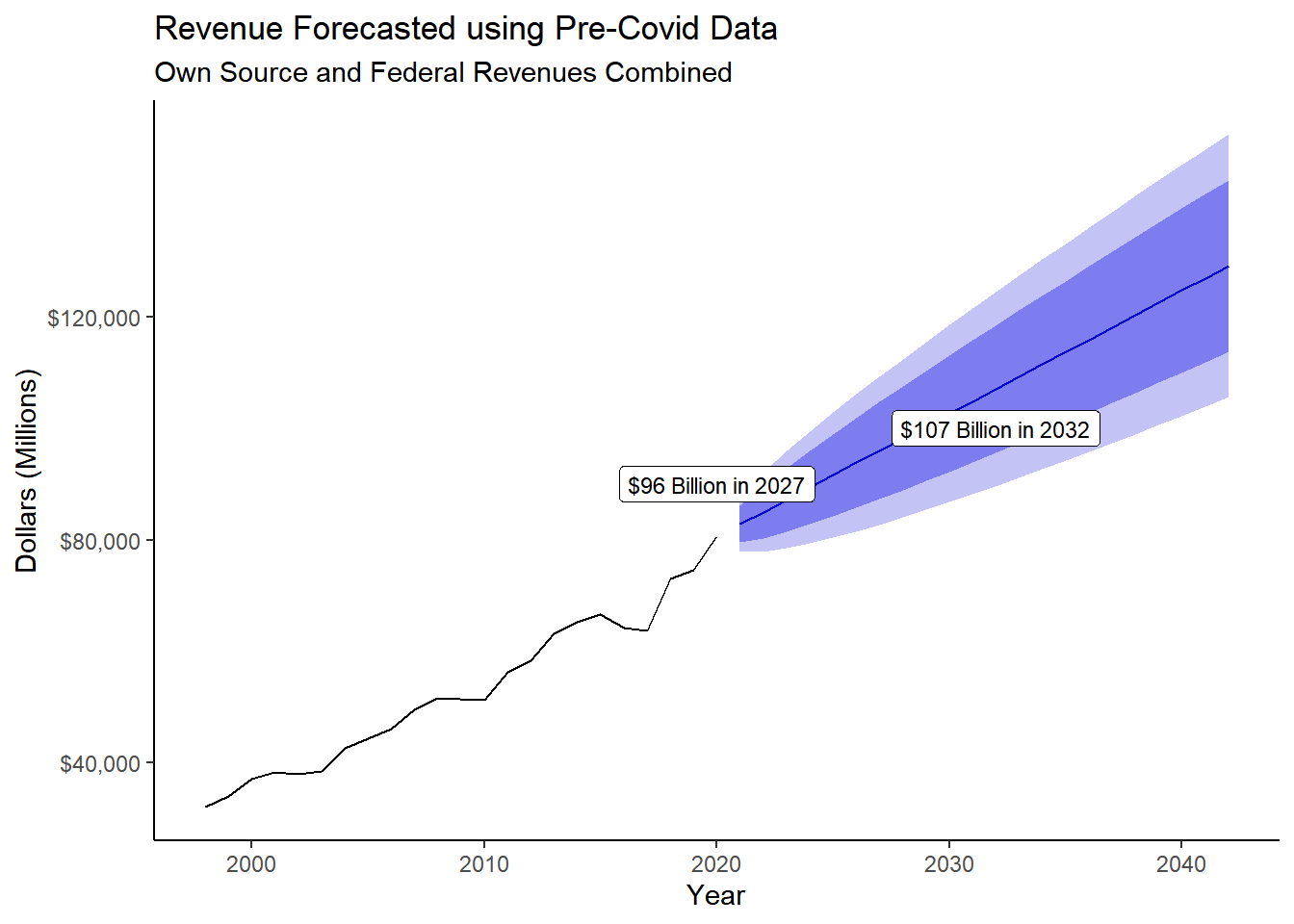
autoplot(tsexp2019) +
#geom_line(tsexp)+
#geom_line(aes(model_rev))+
autolayer(forecast_rev, series = "Revenue") +
autolayer(forecast_exp, series = "Expenditure)", alpha = 0.5) +
geom_line(year_totals, mapping= aes(x = Year, y = Revenue)) + guides(colour = guide_legend("Forecast")) +
labs(title = "Forecasted Revenue and Expenditures", subtitle = "Using Pre-Covid revenue data (ending in FY2020) with Actual 2022 expenditures")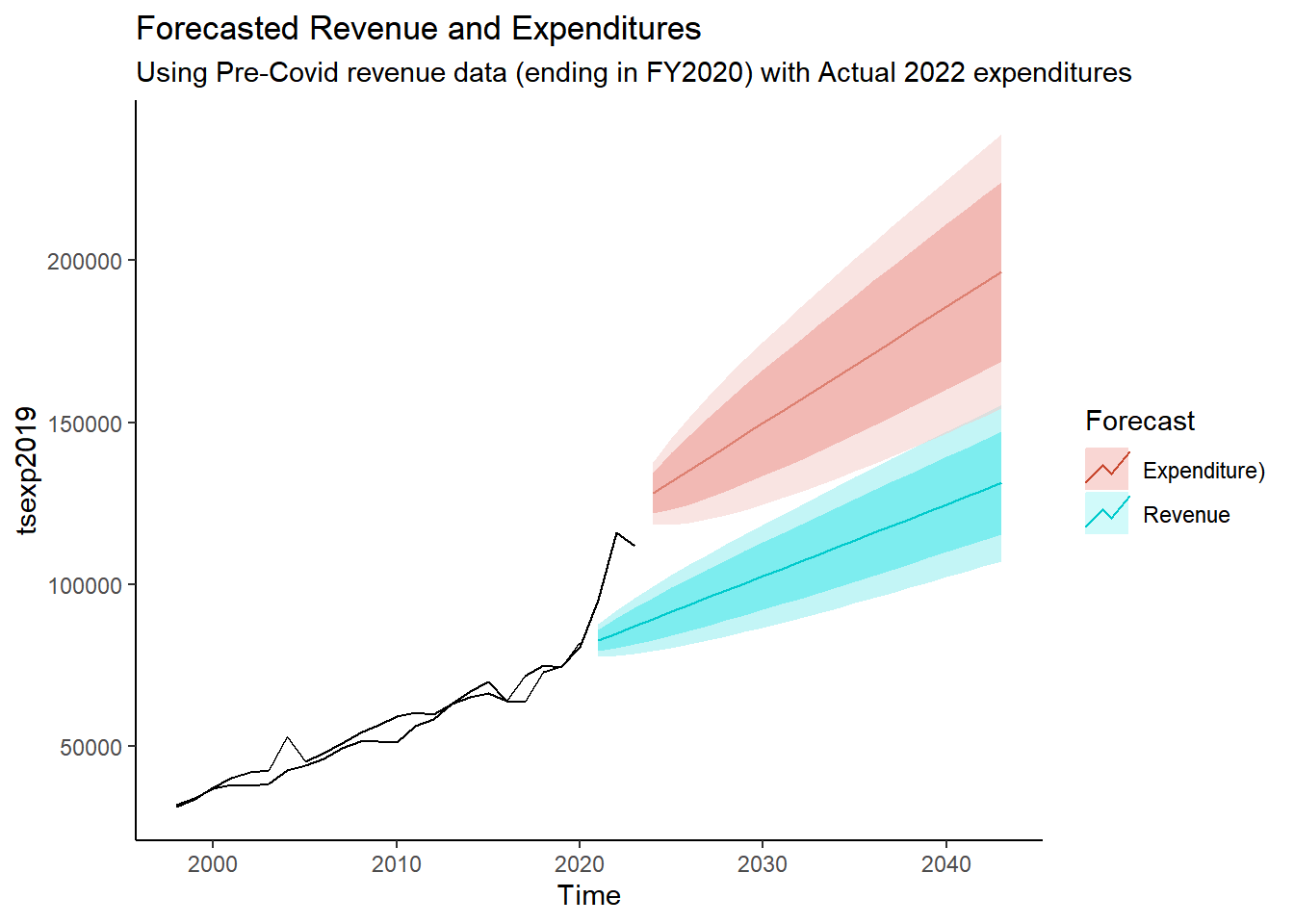
### Federal Revenue
fed_rev <- ff_rev %>% select(fy, rev_57, rev_58, rev_59) %>%
mutate(fed_total = rev_57+rev_58+rev_59)
fed_ts57 <- ts(fed_rev$rev_57, start ="1998", frequency = 1) # yearly data
model_fed <- auto.arima(fed_ts57, seasonal = FALSE)
forecast_fed <- forecast(model_fed, h = 23)
fed57 <- forecast(forecast_fed, h = 20) %>%
autoplot() +
ylab("Nominal Dollars (Millions)") +
xlab("Year") +
ggtitle("Forecasted Federal Other Revenue") +
theme_classic() +
scale_y_continuous(labels = dollar )
fed57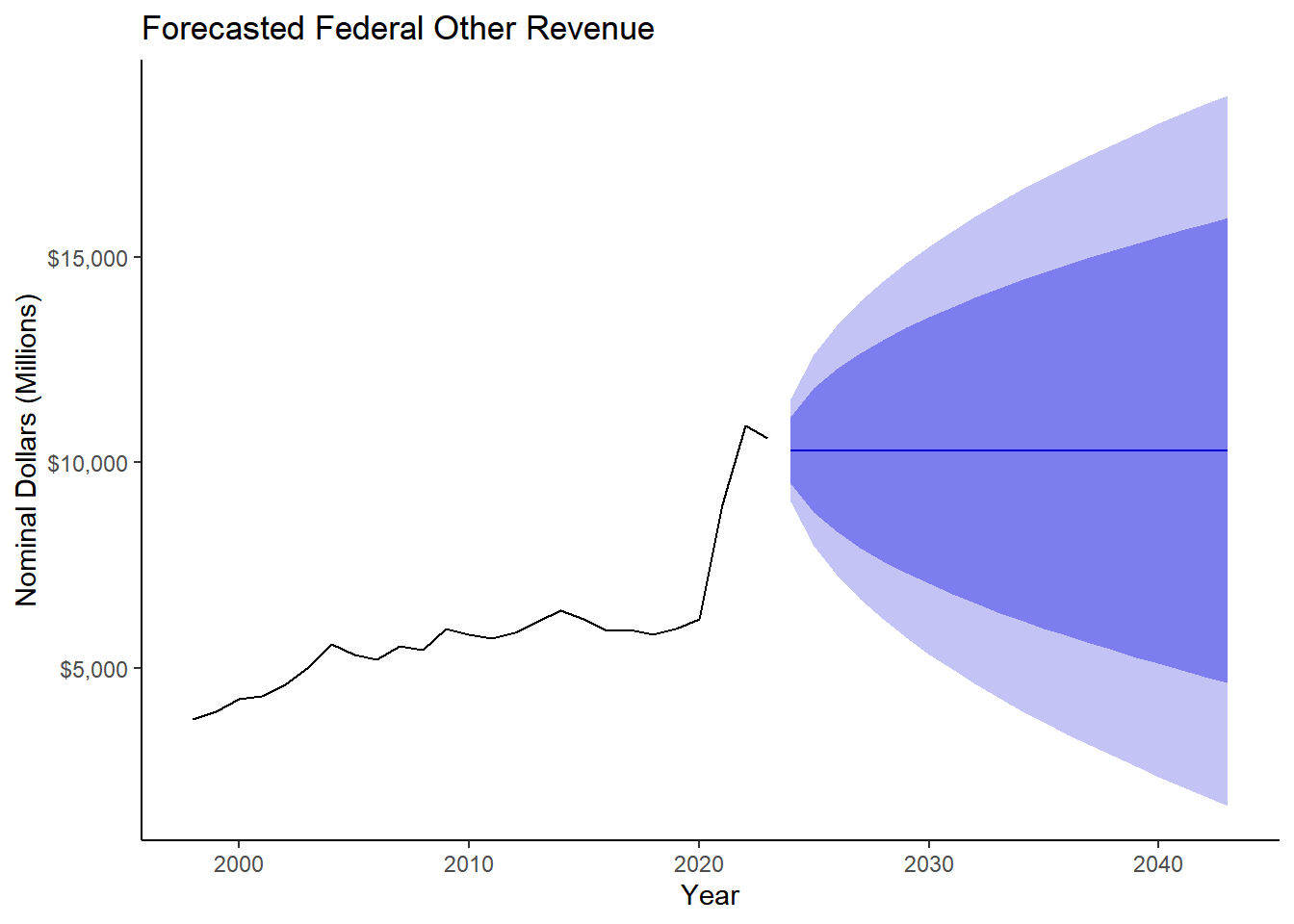
fed_ts58 <- ts(fed_rev$rev_58, start ="1998", frequency = 1) # yearly data
model_fed <- auto.arima(fed_ts58, seasonal = FALSE)
forecast_fed <- forecast(model_fed, h = 23)
fed58 <- forecast(forecast_fed, h = 20) %>%
autoplot() +
ylab("Nominal Dollars (Millions)") +
xlab("Year") +
ggtitle("Forecasted Federal Transfers for Transportation") +
theme_classic() +
scale_y_continuous(labels = dollar )
fed58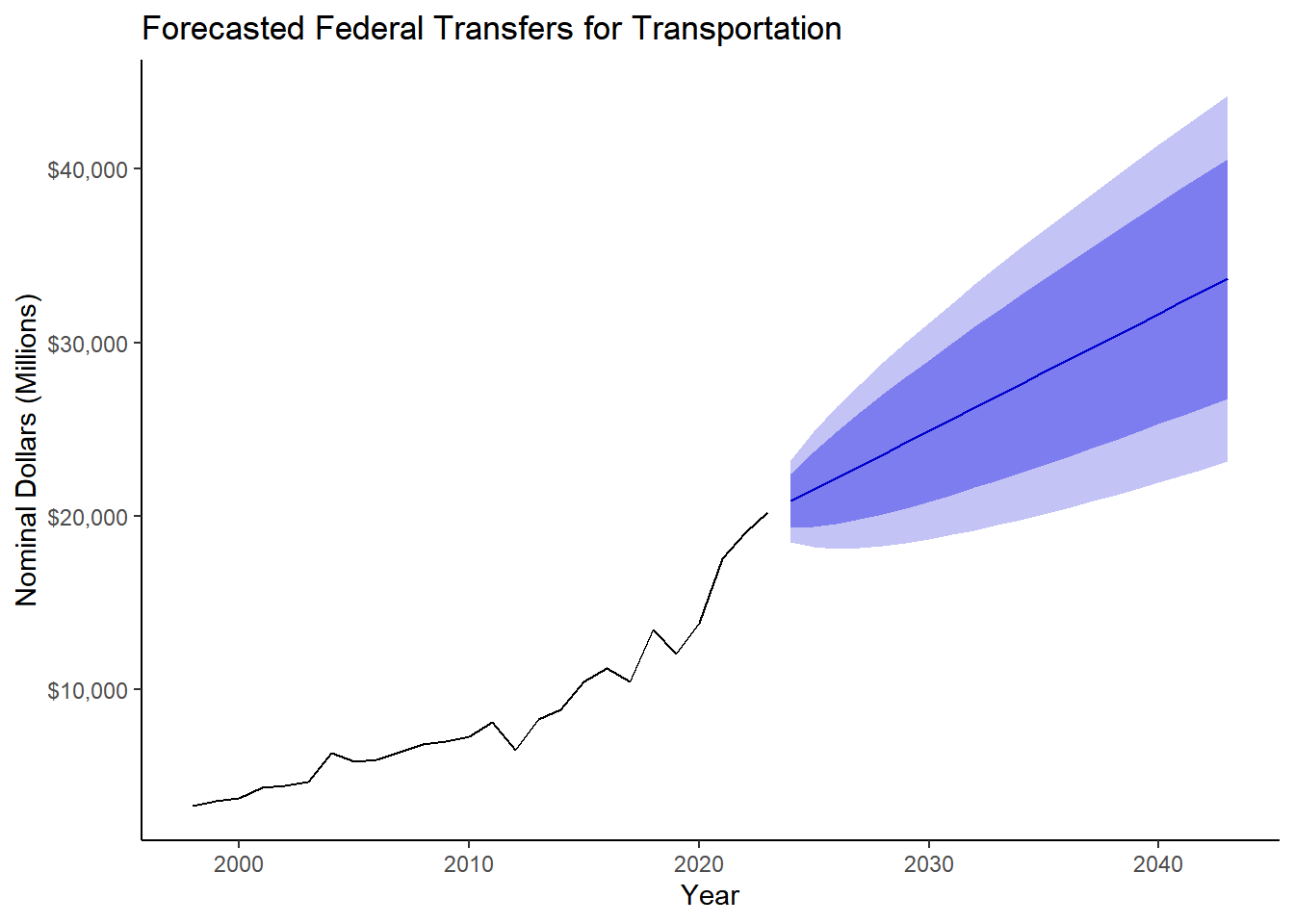
fed_ts59 <- ts(fed_rev$rev_59, start ="1998", frequency = 1) # yearly data
model_fed <- auto.arima(fed_ts59, seasonal = FALSE)
forecast_fed <- forecast(model_fed, h = 23)
fed59 <- forecast(forecast_fed, h = 20) %>%
autoplot() +
ylab("Nominal Dollars (Millions)") +
xlab("Year") +
ggtitle("Forecasted Federal Medicaid Reimbursements") +
theme_classic() +
scale_y_continuous(labels = dollar )
fed59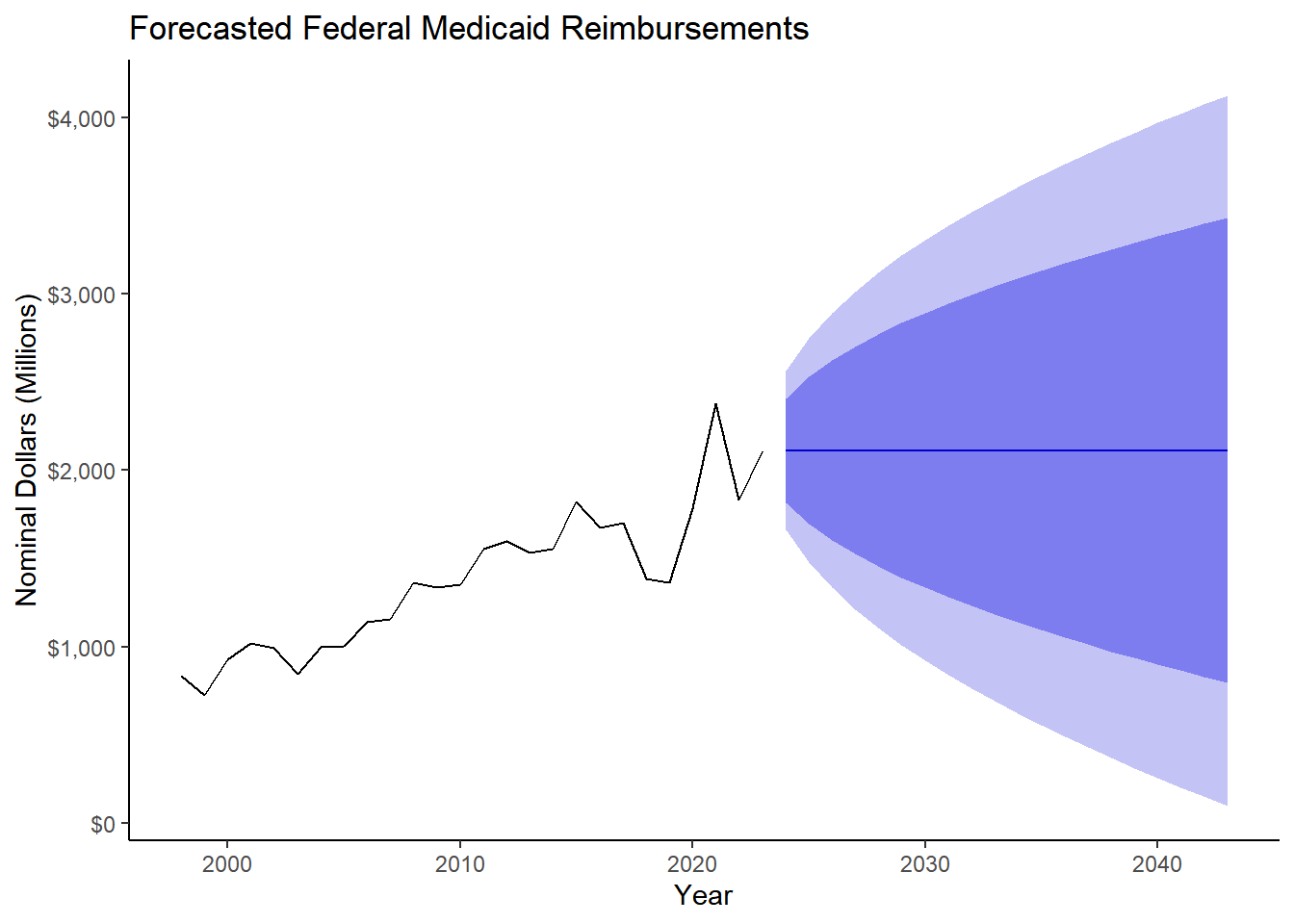
fed_rev <- ff_rev %>% select(fy, rev_57, rev_58, rev_59) %>%
mutate(fed_total = rev_57+rev_58+rev_59)
fed_tstotal <- ts(fed_rev$fed_total, start ="1998", frequency = 1) # yearly data
model_fed <- auto.arima(fed_tstotal, seasonal = FALSE)
forecast_fed <- forecast(model_fed, h = 23)
fedtotal <- forecast(forecast_fed, h = 20) %>%
autoplot() +
ylab("Nominal Dollars (Millions)") +
xlab("Year") +
ggtitle("Forecasted Federal Revenue WITHOUT Federal COVID Dollars", subtitle = "Sum of Transportation, Medicaid, and Other Federal Revenue") +
theme_classic() +
scale_y_continuous(labels = dollar )
fedtotal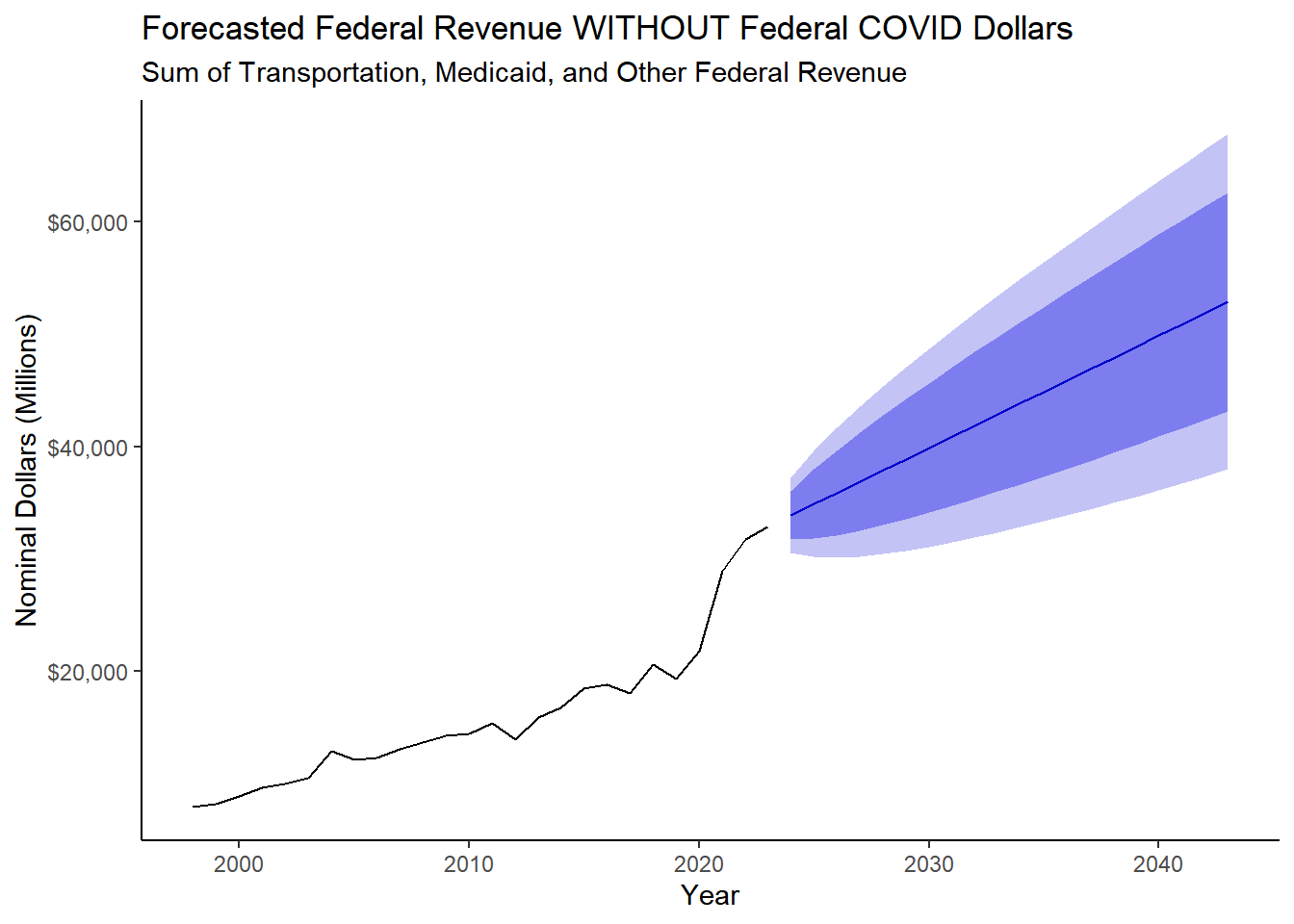
#fed_tstotal <- ts(fed_rev$fed_total, start ="1998", end = "2020", frequency = 1) # yearly data
#model_fed2 <- auto.arima(fed_tstotal, seasonal = FALSE)
#forecast_fed2 <- forecast(model_fed2, h = 23)
# fedtotal2 <- forecast(forecast_fed2, h = 20) %>%
# autoplot() +
# ylab("Nominal Dollars (Millions)") +
# xlab("Year") +
# ggtitle("Forecasted Federal Revenue -- pre-COVID trends", subtitle = "Sum of Transportation, Medicaid, and Other Federal Revenue") +
# theme_classic() +
# scale_y_continuous(labels = dollar )
#
# fedtotal2
autoplot(tsexp2019) +
#geom_line(tsexp)+
#geom_line(aes(model_rev))+
autolayer(forecast_fed, series = "No Fed Stim Packages") +
#autolayer(forecast_fed2, series = "Pre-Covid Fed Rev)", alpha = 0.5) +
geom_line(year_totals2, mapping= aes(x = Year, y = Revenue)) +
guides(colour = guide_legend("Forecast")) +
labs(title = "Comparison of Combined Federal Revenue without Stimulus Packages and \nPre-COVID revenue trend" ,
subtitle = "Using Pre-Covid revenue data (ending in FY2020)")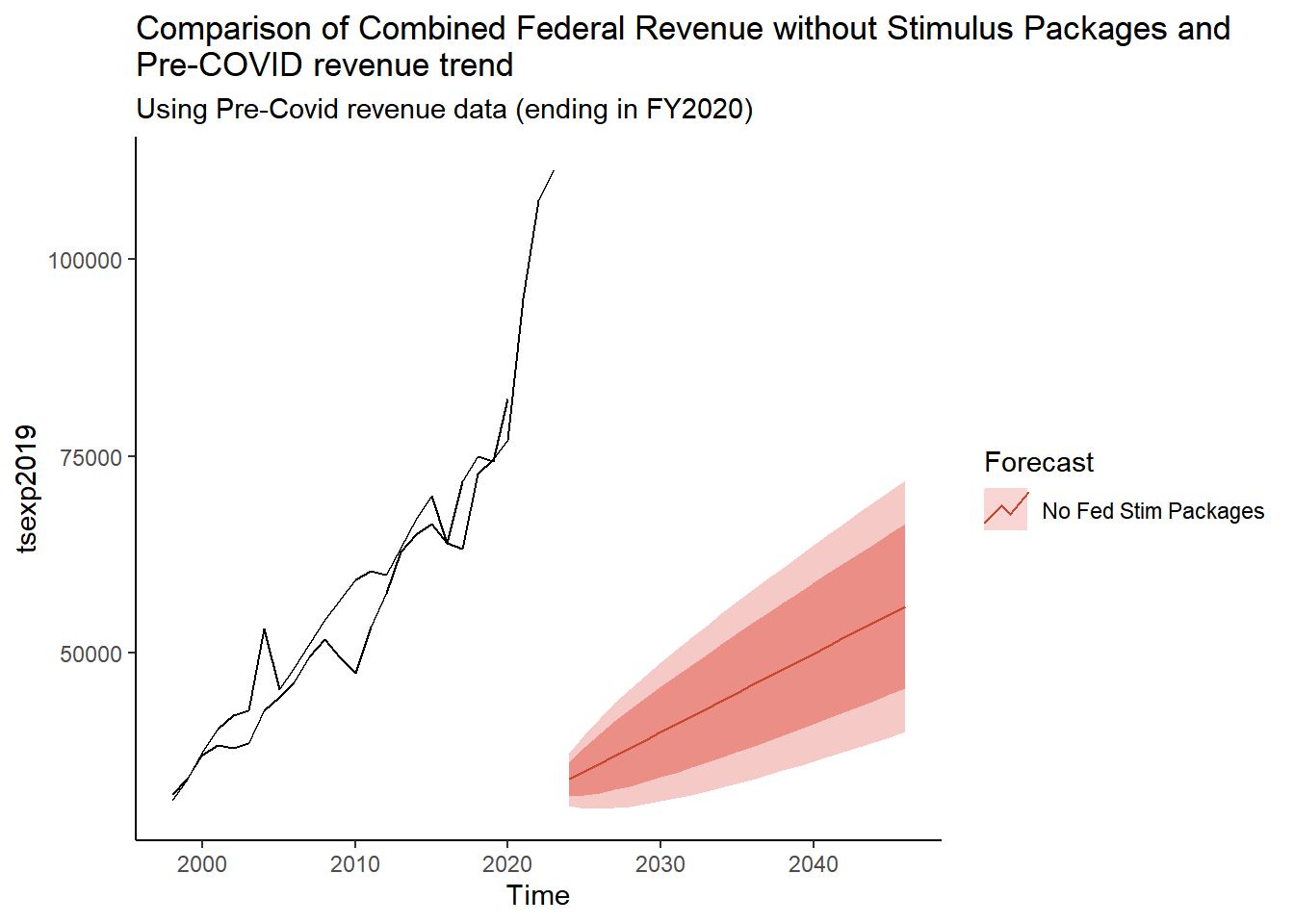
Graphing the 3 federal revenue types together may be the most reliable since some COVID funding is still recorded in Federal Other and some are in other categories (like Disaster Response in FY2021). Need to look at more before using.
# does not include rev_type == 58, medicaid dollars
# covid_dollars <- rev_temp %>% filter(covid_dollars==1) # check what was dropped
#covid_dollars %>% group_by(fy,rev_type) %>% summarize(receipts = sum(receipts)) %>% pivot_wider(names_from="rev_type", values_from = "receipts")
rev_temp <- rev_temp %>% filter(covid_dollars==0) # keeps observations that were not coded as COVID federal funds
ff_rev <- rev_temp %>%
group_by(rev_type_new, fy) %>%
summarize(sum_receipts = sum(receipts, na.rm=TRUE)/1000000 ) %>%
pivot_wider(names_from = "rev_type_new", values_from = "sum_receipts", names_prefix = "rev_")
ff_rev <- mutate_all(ff_rev, ~replace_na(.,0))
rev_long <- pivot_longer(ff_rev, rev_02:rev_78, names_to = c("type","Category"), values_to = "Dollars", names_sep = "_") %>%
rename(Year = fy) %>%
mutate(Category_name = case_when(
Category == "02" ~ "INDIVIDUAL INCOME TAX" ,
Category == "03" ~ "CORPORATE INCOME TAX" ,
Category == "06" ~ "SALES TAX" ,
Category == "09" ~ "MOTOR FUEL TAX" ,
Category == "12" ~ "PUBLIC UTILITY TAX" ,
Category == "15" ~ "CIGARETTE TAXES" ,
Category == "18" ~ "LIQUOR GALLONAGE TAXES" ,
Category == "21" ~ "INHERITANCE TAX" ,
Category == "24" ~ "INSURANCE TAXES&FEES&LICENSES" ,
Category == "27" ~ "CORP FRANCHISE TAXES & FEES" ,
Category == "30" ~ "HORSE RACING TAXES & FEES", # in Other
Category == "31" ~ "MEDICAL PROVIDER ASSESSMENTS" ,
Category == "32" ~ "GARNISHMENT-LEVIES" , # dropped
Category == "33" ~ "LOTTERY RECEIPTS" ,
Category == "35" ~ "OTHER TAXES" ,
Category == "36" ~ "RECEIPTS FROM REVENUE PRODUCING",
Category == "39" ~ "LICENSES, FEES & REGISTRATIONS" ,
Category == "42" ~ "MOTOR VEHICLE AND OPERATORS" ,
Category == "45" ~ "STUDENT FEES-UNIVERSITIES", # dropped
Category == "48" ~ "RIVERBOAT WAGERING TAXES" ,
Category == "51" ~ "RETIREMENT CONTRIBUTIONS" , # dropped
Category == "54" ~ "GIFTS AND BEQUESTS",
Category == "57" ~ "FEDERAL OTHER" ,
Category == "58" ~ "FEDERAL MEDICAID",
Category == "59" ~ "FEDERAL TRANSPORTATION" ,
Category == "60" ~ "OTHER GRANTS AND CONTRACTS", #other
Category == "63" ~ "INVESTMENT INCOME", # other
Category == "66" ~ "PROCEEDS,INVESTMENT MATURITIES" , #dropped
Category == "72" ~ "BOND ISSUE PROCEEDS", #dropped
Category == "75" ~ "INTER-AGENCY RECEIPTS ", #dropped
Category == "76" ~ "TRANSFER IN FROM OUT FUNDS", #other
Category == "78" ~ "ALL OTHER SOURCES" ,
Category == "79" ~ "COOK COUNTY IGT", #dropped
Category == "98" ~ "PRIOR YEAR REFUNDS", #dropped
T ~ "Check Me!"
) )%>%
mutate(Category_name = str_to_title(Category_name))
exp_long <- pivot_longer(ff_exp, exp_402:exp_970 , names_to = c("type", "Category"), values_to = "Dollars", names_sep = "_") %>%
rename(Year = fy ) %>%
mutate(Category_name =
case_when(
Category == "402" ~ "AGING" ,
Category == "406" ~ "AGRICULTURE",
Category == "416" ~ "CENTRAL MANAGEMENT",
Category == "418" ~ "CHILDREN AND FAMILY SERVICES",
Category == "420" ~ "COMMERCE AND ECONOMIC OPPORTUNITY",
Category == "422" ~ "NATURAL RESOURCES" ,
Category == "426" ~ "CORRECTIONS",
Category == "427" ~ "EMPLOYMENT SECURITY" ,
Category == "444" ~ "HUMAN SERVICES" ,
Category == "448" ~ "Innovation and Technology", # AWM added fy2022
Category == "478" ~ "HEALTHCARE & FAM SER NET OF MEDICAID",
Category == "482" ~ "PUBLIC HEALTH",
Category == "492" ~ "REVENUE",
Category == "494" ~ "TRANSPORTATION" ,
Category == "532" ~ "ENVIRONMENTAL PROTECT AGENCY" ,
Category == "557" ~ "IL STATE TOLL HIGHWAY AUTH" ,
Category == "684" ~ "IL COMMUNITY COLLEGE BOARD",
Category == "691" ~ "IL STUDENT ASSISTANCE COMM" ,
Category == "900" ~ "NOT IN FRAME",
Category == "901" ~ "STATE PENSION CONTRIBUTION",
Category == "903" ~ "DEBT SERVICE",
Category == "904" ~ "State Employee Healthcare",
Category == "910" ~ "LEGISLATIVE" ,
Category == "920" ~ "JUDICIAL" ,
Category == "930" ~ "ELECTED OFFICERS" ,
Category == "940" ~ "OTHER HEALTH-RELATED",
Category == "941" ~ "PUBLIC SAFETY" ,
Category == "942" ~ "ECON DEVT & INFRASTRUCTURE" ,
Category == "943" ~ "CENTRAL SERVICES",
Category == "944" ~ "BUS & PROFESSION REGULATION" ,
Category == "945" ~ "MEDICAID" ,
Category == "946" ~ "CAPITAL IMPROVEMENT" ,
Category == "948" ~ "OTHER DEPARTMENTS" ,
Category == "949" ~ "OTHER BOARDS & COMMISSIONS" ,
Category == "959" ~ "K-12 EDUCATION" ,
Category == "960" ~ "UNIVERSITY EDUCATION",
Category == "970" ~ "Local Govt Transfers",
T ~ "CHECK ME!")
) %>%
mutate(Category_name = str_to_title(Category_name))
#exp_long_nototals <- exp_long %>% filter(Category_name != "Totals")
aggregated_totals_long <- rbind(rev_long, exp_long) Change plots:
year_totals2 <- aggregated_totals_long %>%
group_by(type, Year) %>%
summarize(Dollars = sum(Dollars, na.rm = TRUE)) %>%
pivot_wider(names_from = "type", values_from = Dollars) %>%
rename(
Expenditures = exp,
Revenue = rev) %>%
mutate(`Fiscal Gap` = round(Revenue - Expenditures)) %>%
arrange(desc(Year))
# creates variable for the Gap each year
year_totals2 # gap for FY22 changed to ~2 or 3 billionannotation_billions <- data.frame(
x = c(2004, 2017, 2019),
y = c(60, 50, 10),
label = c("Expenditures","Revenue", "Fiscal Gap"))
fiscal_gap1 <- ggplot(data = year_totals, aes(x=Year, y = Revenue/1000)) +
geom_recessions(text = FALSE)+
geom_hline(yintercept = 0) +
geom_line(aes(x = Year, y = Revenue/1000), color = "Black", lwd=1) +
geom_line(aes(x = Year, y = Expenditures/1000, linetype = "dashed"), color = "red", lwd=1) +
geom_line(aes(x = Year, y = `Fiscal Gap`/1000), color = "gray") +
geom_text(data = annotation_billions, aes(x=x, y=y, label=label))+
theme_classic() +
theme(legend.position = "none", #axis.text.y = element_blank(),
#axis.ticks.y = element_blank(),
axis.title.y = element_blank())+
scale_linetype_manual(values = c("dashed", "dashed")) +
scale_y_continuous(limits = c(-16, 120), labels = comma)+
scale_x_continuous(limits=c(1998,2023), expand = c(0,0))
fiscal_gap1
#ggsave(fiscal_gap1, file = "Figure7a-WithCURE.eps")
fiscal_gap_droppedCURE <- ggplot(data = year_totals2, aes(x=Year, y = Revenue/1000)) +
geom_recessions(text = FALSE)+
geom_hline(yintercept=0)+
geom_hline(yintercept = 0) +
geom_line(aes(x = Year, y = Revenue/1000), color = "Black", lwd=1) +
geom_line(aes(x = Year, y = Expenditures/1000, linetype = "dashed"), color = "red", lwd=1) +
geom_line(aes(x = Year, y = `Fiscal Gap`/1000), color = "gray") +
geom_text(data = annotation_billions, aes(x=x, y=y, label=label))+
theme_classic() +
theme(legend.position = "none",# axis.text.y = element_blank(),
#axis.ticks.y = element_blank(),
axis.title.y = element_blank() )+
scale_linetype_manual(values = c("dashed", "dashed")) +
scale_y_continuous(limits=c(-16,120), labels = comma)+
scale_x_continuous(limits=c(1998,2023),expand = c(0,0))
# # geom_smooth adds regression line, graphed first so it appears behind line graph
# geom_smooth(aes(x = Year, y = Revenue), color = "gray", method = "lm", se = FALSE) +
# geom_smooth(aes(x = Year, y = Expenditures), color = "rosybrown2", method = "lm", se = FALSE) +
#
# # line graph of revenue and expenditures
# geom_line(aes(x = Year, y = Revenue), color = "black", size=1) +
# geom_line(aes(x = Year, y = Expenditures), color = "red", size=1) +
# geom_line(aes(x=Year, y = `Fiscal Gap`), color="gray") +
#
# geom_text(data= annotation, aes(x=x, y = y, label=label))+
#
# # labels
# theme_bw() +
# scale_y_continuous(labels = comma)+
# xlab("Year") +
# ylab("Millions of Dollars") +
# ggtitle("Illinois Expenditures and Revenue Totals, 1998-2022")
fiscal_gap_droppedCURE
#ggsave(fiscal_gap_droppedCURE, file = "Figure7b-WithoutCURE.eps")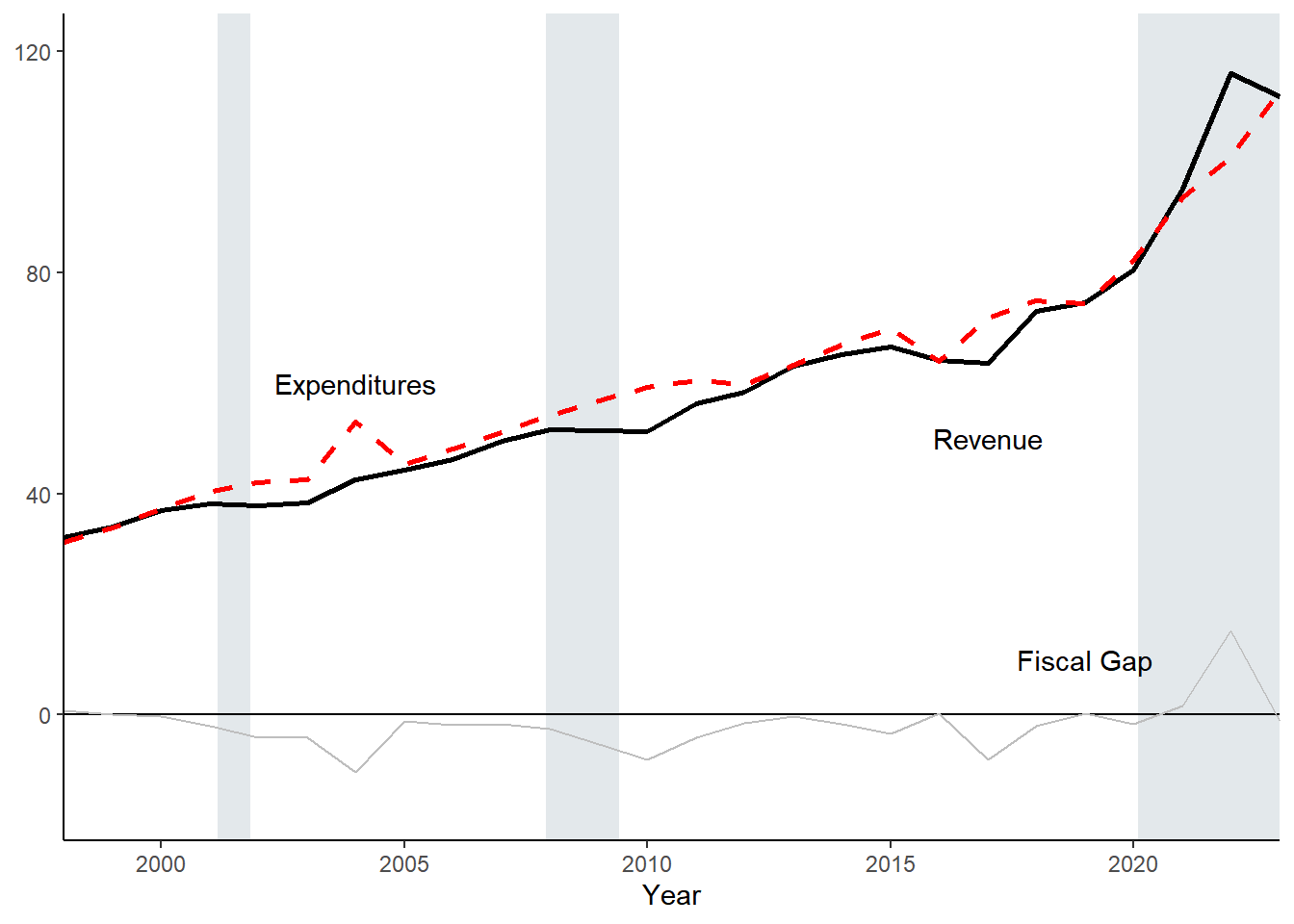
Compare with and without federal COVID dollars:
Revenue amounts in millions of dollars:
rev_long %>%
filter(Year == 2023) %>%
#mutate(`Total Expenditures`= sum(Dollars, na.rm = TRUE)) %>%
# select(-c(Year, `Total Expenditures`)) %>%
arrange(desc(`Dollars`)) %>%
ggplot() +
geom_col(aes(x = fct_reorder(Category_name, `Dollars`), y = `Dollars`))+
coord_flip() +
theme_bw() +
labs(title = "Revenues for FY2023")+
xlab("Revenue Categories") +
ylab("Millions of Dollars")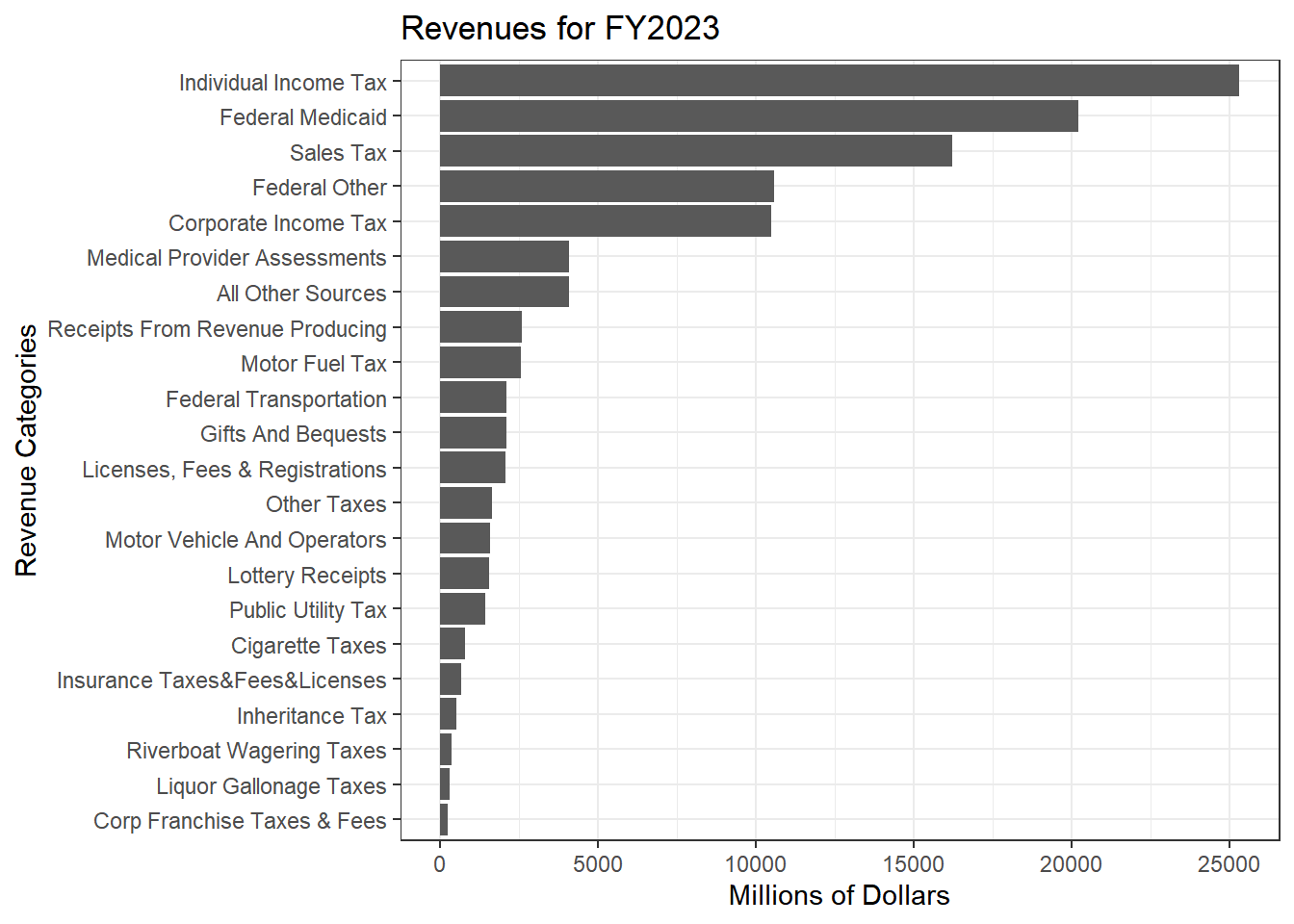
exp_totals <- ff_exp %>% rowwise() %>% mutate(exp_TOTALS = sum(across(exp_402:exp_970)))
rev_totals <- ff_rev %>% rowwise() %>%
mutate(rev_TOTALS = sum(across(rev_02:rev_78)))
rev_long <- pivot_longer(rev_totals, rev_02:rev_TOTALS, names_to = c("type","Category"), values_to = "Dollars", names_sep = "_") %>%
rename(Year = fy) %>%
mutate(Category_name = case_when(
Category == "02" ~ "INDIVIDUAL INCOME TAXES" ,
Category == "03" ~ "CORPORATE INCOME TAXES" ,
Category == "06" ~ "SALES TAXES" ,
Category == "09" ~ "MOTOR FUEL TAX" ,
Category == "12" ~ "PUBLIC UTILITY TAXES" ,
Category == "15" ~ "CIGARETTE TAXES" ,
Category == "18" ~ "LIQUOR GALLONAGE TAXES" ,
Category == "21" ~ "INHERITANCE TAX" ,
Category == "24" ~ "INSURANCE TAXES&FEES&LICENSES" ,
Category == "27" ~ "CORP FRANCHISE TAXES & FEES" ,
Category == "30" ~ "HORSE RACING TAXES & FEES", # in Other
Category == "31" ~ "MEDICAL PROVIDER ASSESSMENTS" ,
Category == "32" ~ "GARNISHMENT-LEVIES" , # dropped
Category == "33" ~ "LOTTERY RECEIPTS" ,
Category == "35" ~ "OTHER TAXES" ,
Category == "36" ~ "RECEIPTS FROM REVENUE PRODUCING",
Category == "39" ~ "LICENSES, FEES & REGISTRATIONS" ,
Category == "42" ~ "MOTOR VEHICLE AND OPERATORS" ,
Category == "45" ~ "STUDENT FEES-UNIVERSITIES", # dropped
Category == "48" ~ "RIVERBOAT WAGERING TAXES" ,
Category == "51" ~ "RETIREMENT CONTRIBUTIONS" , # dropped
Category == "54" ~ "GIFTS AND BEQUESTS",
Category == "57" ~ "FEDERAL OTHER" ,
Category == "58" ~ "FEDERAL MEDICAID",
Category == "59" ~ "FEDERAL TRANSPORTATION" ,
Category == "60" ~ "OTHER GRANTS AND CONTRACTS", #other
Category == "63" ~ "INVESTMENT INCOME", # other
Category == "66" ~ "PROCEEDS,INVESTMENT MATURITIES" , #dropped
Category == "72" ~ "BOND ISSUE PROCEEDS", #dropped
Category == "75" ~ "INTER-AGENCY RECEIPTS ", #dropped
Category == "76" ~ "TRANSFER IN FROM OUT FUNDS", #other
Category == "78" ~ "ALL OTHER SOURCES" ,
Category == "79" ~ "COOK COUNTY IGT", #dropped
Category == "98" ~ "PRIOR YEAR REFUNDS", #dropped
Category == "TOTALS" ~ "Total"
) ) %>%
select(-type, -Category) %>% # drop extra columns type and Category number
group_by(Year, Category_name) %>%
summarise(Dollars= round(sum(Dollars),digits=2)) %>%
mutate(Category_name = str_to_title(Category_name))
# creates wide version of table where each revenue source is a column
revenue_wide2 <- rev_long %>% pivot_wider(names_from = Category_name,
values_from = Dollars) %>%
# relocate("Other Revenue Sources **", .after = last_col()) %>%
relocate("Total", .after = last_col())exp_long <- pivot_longer(exp_totals, exp_402:exp_TOTALS , names_to = c("type", "Category"), values_to = "Dollars", names_sep = "_") %>%
rename(Year = fy ) %>%
mutate(Category_name =
case_when(
Category == "402" ~ "AGING" ,
Category == "406" ~ "AGRICULTURE",
Category == "416" ~ "Central Management",
Category == "418" ~ "CHILDREN AND FAMILY SERVICES",
Category == "420" ~ "Community Development",
Category == "422" ~ "NATURAL RESOURCES" ,
Category == "426" ~ "CORRECTIONS",
Category == "427" ~ "EMPLOYMENT SECURITY" ,
Category == "444" ~ "Human Services" ,
Category == "478" ~ "HEALTHCARE & FAM SER NET OF MEDICAID",
Category == "482" ~ "PUBLIC HEALTH",
Category == "492" ~ "REVENUE",
Category == "494" ~ "Transportation" ,
Category == "532" ~ "ENVIRONMENTAL PROTECT AGENCY" ,
Category == "557" ~ "Tollway" ,
Category == "684" ~ "IL COMMUNITY COLLEGE BOARD",
Category == "691" ~ "IL STUDENT ASSISTANCE COMM" ,
Category == "900" ~ "NOT IN FRAME",
Category == "901" ~ "State Pension Contribution",
Category == "903" ~ "Debt Service",
Category == "904" ~ "State Employee Healthcare",
Category == "910" ~ "LEGISLATIVE" ,
Category == "920" ~ "JUDICIAL" ,
Category == "930" ~ "ELECTED OFFICERS" ,
Category == "940" ~ "OTHER HEALTH-RELATED",
Category == "941" ~ "Public Safety" ,
Category == "942" ~ "ECON DEVT & INFRASTRUCTURE" ,
Category == "943" ~ "CENTRAL SERVICES",
Category == "944" ~ "BUS & PROFESSION REGULATION" ,
Category == "945" ~ "Medicaid" ,
Category == "946" ~ "Capital Improvement" ,
Category == "948" ~ "OTHER DEPARTMENTS" ,
Category == "949" ~ "OTHER BOARDS & COMMISSIONS" ,
Category == "959" ~ "K-12 Education" ,
Category == "960" ~ "UNIVERSITY EDUCATION",
Category == "970" ~ "Local Govt Revenue Sharing",
Category == "TOTALS" ~ "Total") #,T ~ "All Other Expenditures **")
) %>%
select(-type, -Category) %>%
group_by(Year, Category_name) %>%
summarise(Dollars= round(sum(Dollars),digits=2)) %>%
mutate(Category_name = str_to_title(Category_name))
expenditure_wide2 <- exp_long%>%
pivot_wider(names_from = Category_name,
values_from = Dollars) %>%
#relocate("All Other Expenditures **", .after = last_col()) %>%
relocate("Total", .after = last_col())