Code refunds to match the rev_type codes (02=income taxes, 03 = corporate income taxes, 06=sales tax, 09=motor fuel tax, 24=insurance taxes and fees, 35 = all other tax refunds).
Ideally the money going in and out of the funds used for refunds would be approximately equal. If equal, would drop from Fiscal Futures analysis so that Revenue reflects the amount of money the state gets to keep (and the local portion that becomes the local govt transfer)
Code
# What we want: To exclude refunds as expenditures from our expenditure totals.# Exclude funds that hold refund funds from both revenue and expenditure sides# Revenue neutral unless budget tricks are occurring# still want to examine refunds over time to compare to past years calculations# fund 0278 was set to in_ff == 0 so it would have been ignored from the revenue and expenditure side.tax_refund_long <- exp_temp %>%# fund != "0401" # Protest Trust Fundfilter(fund !="0401"&# don't know why this was included? (object =="9900"| object =="9910"| object =="9921"| object =="9923"| object =="9925") ) %>%# keeps these objects which represent revenue, insurance, treasurer,and financial and professional reg tax refundsmutate(refund =case_when( object =="9900"~"FY23_Rebates", # part of COVID Relief fund =="0278"& sequence =="00"~"02", # for income tax refund fund =="0278"& sequence =="01"~"03", # tax administration and enforcement and tax operations become corporate income tax refund fund =="0278"& sequence =="02"~"02", object=="9921"~"21", # inheritance tax and estate tax refund appropriation object=="9923"| fund =="0012"~"09", # motor fuel tax refunds obj_seq_type =="99250055"~"06", # sales tax refund, fund=="0378"& object=="9925"~"24", # insurance privilege tax refund (fund=="0001"& object=="9925") | (fund =="0384"& object=="9925"& fy ==2023) ~"35", # all other taxes# fund=="0001" & object=="9925" ~ "35", # all other taxes T ~"CHECK")) # if none of the items above apply to the observations, then code them as CHECK exp_temp <-left_join(exp_temp, tax_refund_long) %>%mutate(refund =ifelse(is.na(refund),"not refund", as.character(refund)))tax_refund <- tax_refund_long %>%group_by(refund, fy)%>%summarize(refund_amount =sum(expenditure, na.rm =TRUE)/1000000) %>%pivot_wider(names_from = refund, values_from = refund_amount, names_prefix ="ref_") %>%mutate_all(~replace_na(.,0)) %>%arrange(fy)tax_refund %>%pivot_longer(c(ref_02:ref_35, ref_FY23_Rebates), names_to ="Refund Type", values_to ="Amount") %>%ggplot()+theme_classic()+geom_line(aes(x=fy,y=Amount, group =`Refund Type`, color =`Refund Type`))+labs(title ="Refund Types", caption ="Refunds are excluded from Expenditure totals and instead subtracted from Revenue totals") +labs(title ="Tax refunds", caption ="Rev_type codes: 02=income taxes, 03=corporate income taxes, 06=sales tax, 09=motor fuel tax, 24=insurance taxes and fees, 35 = all other tax refunds." )# remove the items we recoded in tax_refund_long# keep only non-refund expenditures with filter()# exp_temp <- exp_temp %>% filter(refund == "not refund")
Figure 1.1: Tax Refunds
For FY23, the one-time abatement, object 9900, is included as an expenditure item within the Department of Revenue.
Code
# manually adds the abatements as expenditure item and keeps on expenditure side.# otherwise ignored since it is in fund 0278 and exp_temp <- exp_temp %>%mutate(in_ff =if_else(object ==9900, 1, in_ff))
1.1.2 Pension Expenditures
State pension contributions are largely captured with object=4431. (State payments into pension fund). State payments to the following pension systems:
Teachers Retirement System (TRS)
New POB bond in 2019: Accelerated Bond Fund paid benefits in advance as lump sum
State Employee Retirement System (SERS)
State University Retirement System (SURS)
Judges Retirement System (JRS)
General Assembly Retirement System (GARS)
Modify exp_temp and move all state pension contributions to their own group (901). For more information on the variables included or excluded, please see Chapter 8.
Code
exp_temp <- exp_temp %>%arrange(fund) %>%mutate(pension =case_when( (object=="4431") ~1, # 4431 = easy to find pension payments INTO fund (object>"1159"& object<"1166") & fund !="0183"& fund !="0193"~2, # objects 1159 to 1166 are all considered Retirement by Comptroller, # Included - employer contributions from agencies/organizations/etc. (object=="1298"&# Purchase of Investments, Normally excluded (fy==2010| fy==2011) & (fund=="0477"| fund=="0479"| fund=="0481")) ~3, #judges retirement OUT of fund# state borrowed money from pension funds to pay for core services during 2010 and 2011. # used to fill budget gap and push problems to the future. fund =="0319"~4, # pension stabilization fundTRUE~0) )table(exp_temp$pension)
0 1 2 3 4
240897 248 9239 6 21
Code
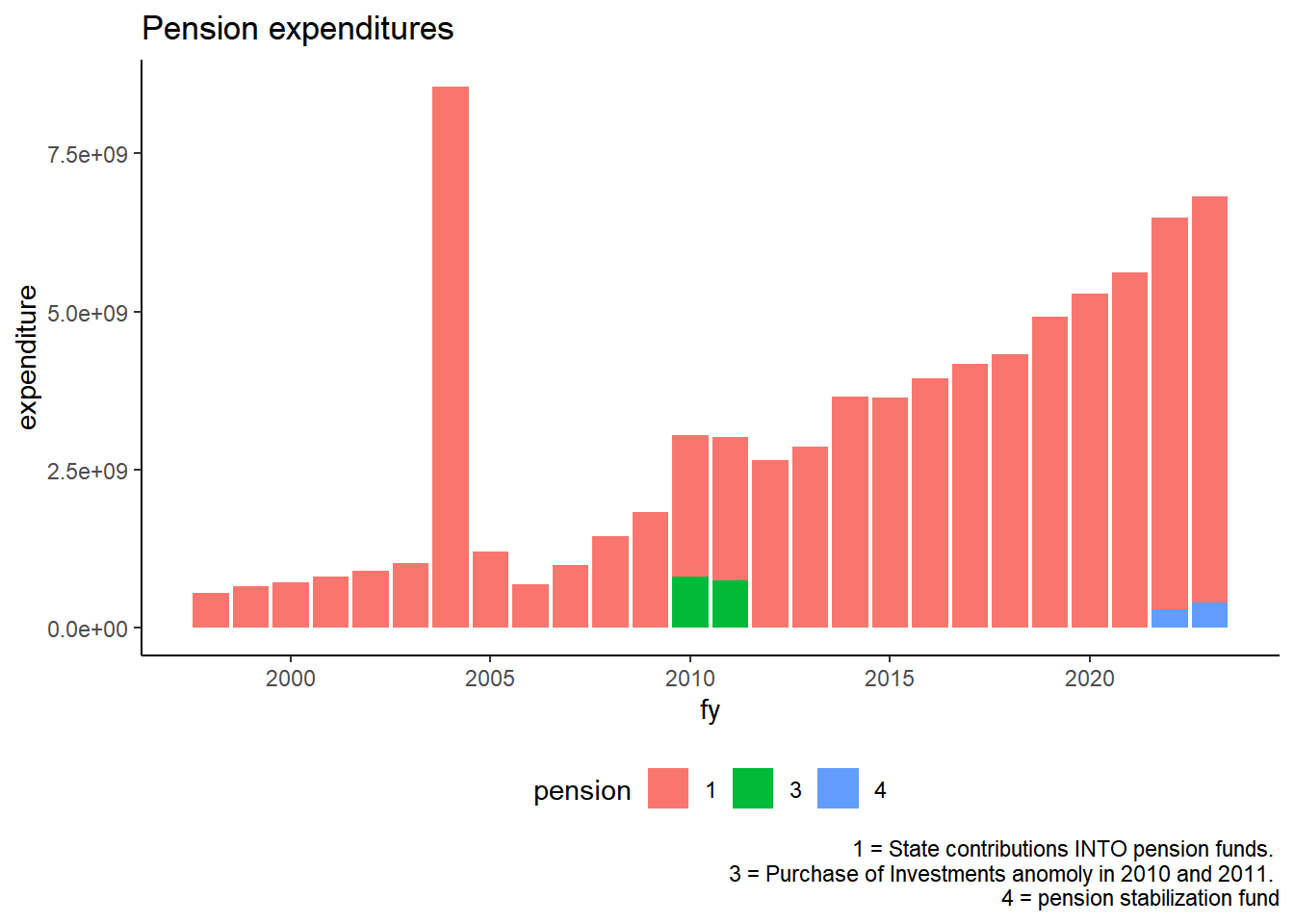
exp_temp %>%filter(pension !=0) %>%mutate(pension =as.factor(pension))%>%group_by(fy, pension) %>%summarize(expenditure =sum(expenditure, na.rm =TRUE)) %>%ggplot(aes(x=fy, y = expenditure, group=pension)) +theme_classic()+geom_col(aes(fill = pension)) +labs (title ="Pension expenditures", caption ="1 = State contributions INTO pension funds. 2 = Employer Contributions. 3 = Purchase of Investments anomoly in 2010 and 2011. 4 = pension stabilization fund")+theme(legend.position ="bottom")
Figure 1.2: Pensions
Code
# special accounting of pension obligation bond (POB)-funded contributions to JRS, SERS, GARS, TRS exp_temp <- exp_temp %>%# change object for 2010 and 2011, retirement expenditures were bond proceeds and would have been excludedmutate(object =ifelse((pension >0& in_ff =="0"), "4431", object)) %>%# changes weird teacher & judge retirement system pensions object to normal pension object 4431mutate(pension =ifelse(pension >0& in_ff =="0", 6, pension)) %>%# coded as 6 if it was supposed to be excluded. mutate(in_ff =ifelse(pension >0, "1", in_ff))table(exp_temp$pension)
0 1 2 4 6
240897 246 9100 20 147
Code
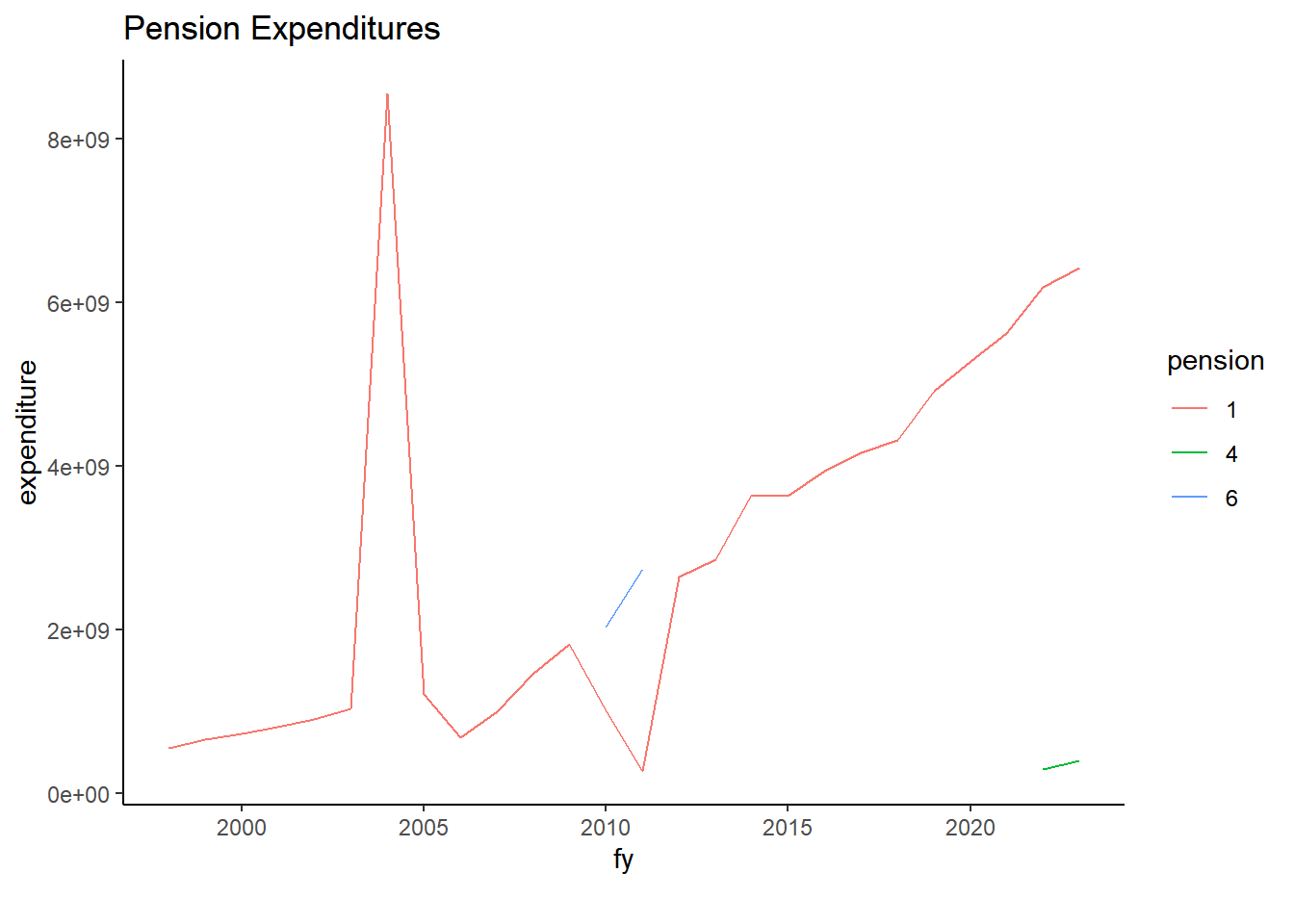
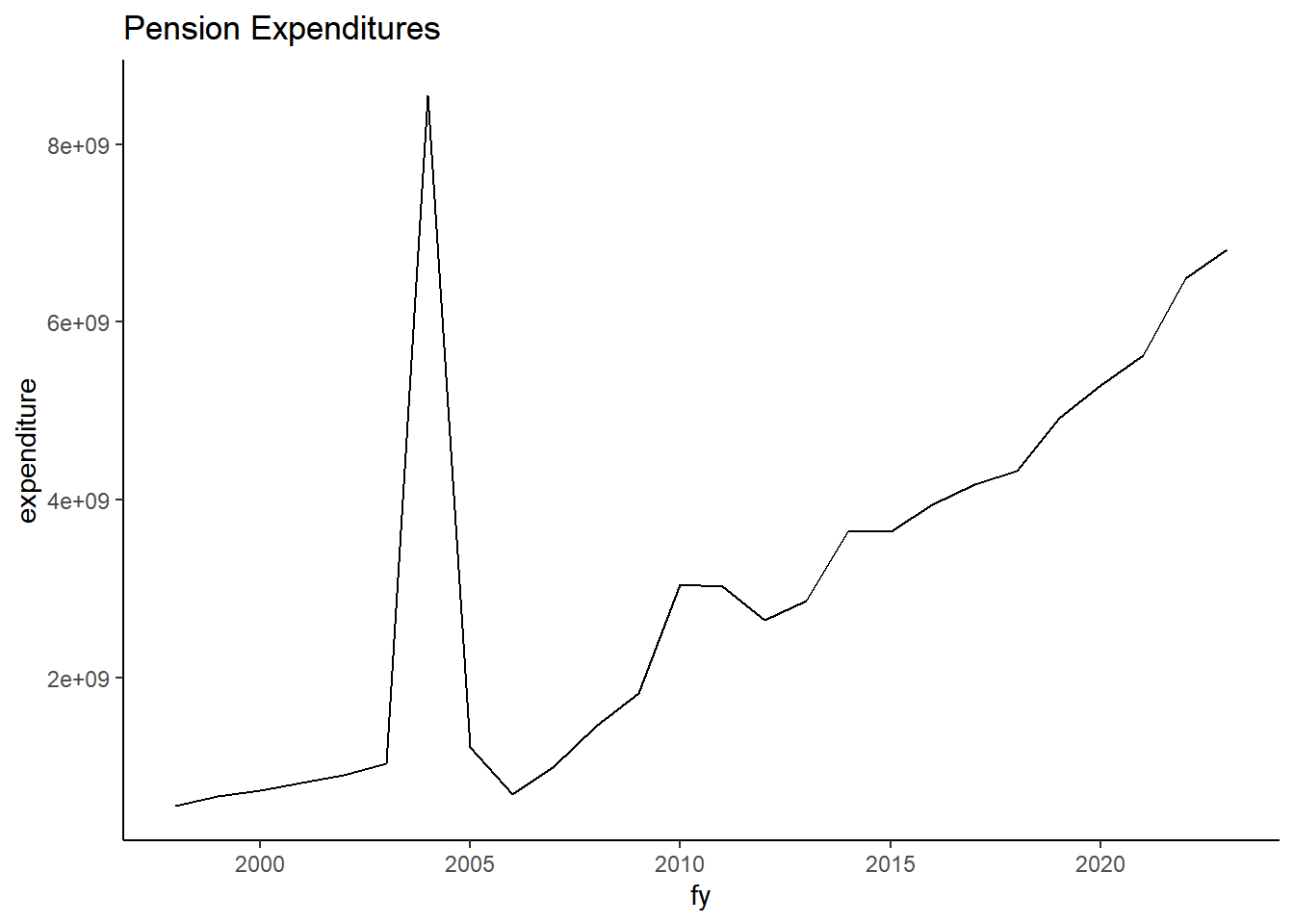
# all other pensions objects codes get agency code 901 for State Pension Contributionsexp_temp <- exp_temp %>%mutate(agency =ifelse(pension>0, "901", as.character(agency)),agency_name =ifelse(agency =="901", "State Pension Contributions", as.character(agency_name)))exp_temp %>%filter(pension >0) %>%mutate(pension =as.factor(pension)) %>%group_by(fy, pension) %>%summarize(expenditure =sum(expenditure, na.rm=TRUE)) %>%ggplot(aes(x=fy, y=expenditure, color = pension)) +geom_line() +theme_classic()+labs (title ="Pension Expenditures", caption ="")exp_temp %>%filter(pension >0) %>%group_by(fy) %>%summarize(expenditure =sum(expenditure, na.rm=TRUE)) %>%ggplot(aes(x=fy, y=expenditure)) +geom_line() +theme_classic()+labs (title ="Pension Expenditures")
Figure 1.3: Pension Expenditures
Figure 1.4: Pension Expenditures
1.1.3 Drop Interfund transfers
Drop all cash transfers between funds, statutory transfers, and purchases of investments from expenditure data.
object == 1993 is for interfund cash transfers
agency == 799 is for statutory transfers
object == 1298 is for purchase of investments and is not spending EXCEPT for costs in 2010 and 2011 (and were recoded already to object == “4431”). Over 168,000 observations remain.
# always check to make sure you aren't accidently dropping something of interest.exp_temp <-anti_join(exp_temp, transfers_drop)refunds_drop <- exp_temp %>%filter(object %in%c())exp_temp <-anti_join(exp_temp, refunds_drop)exp_temp
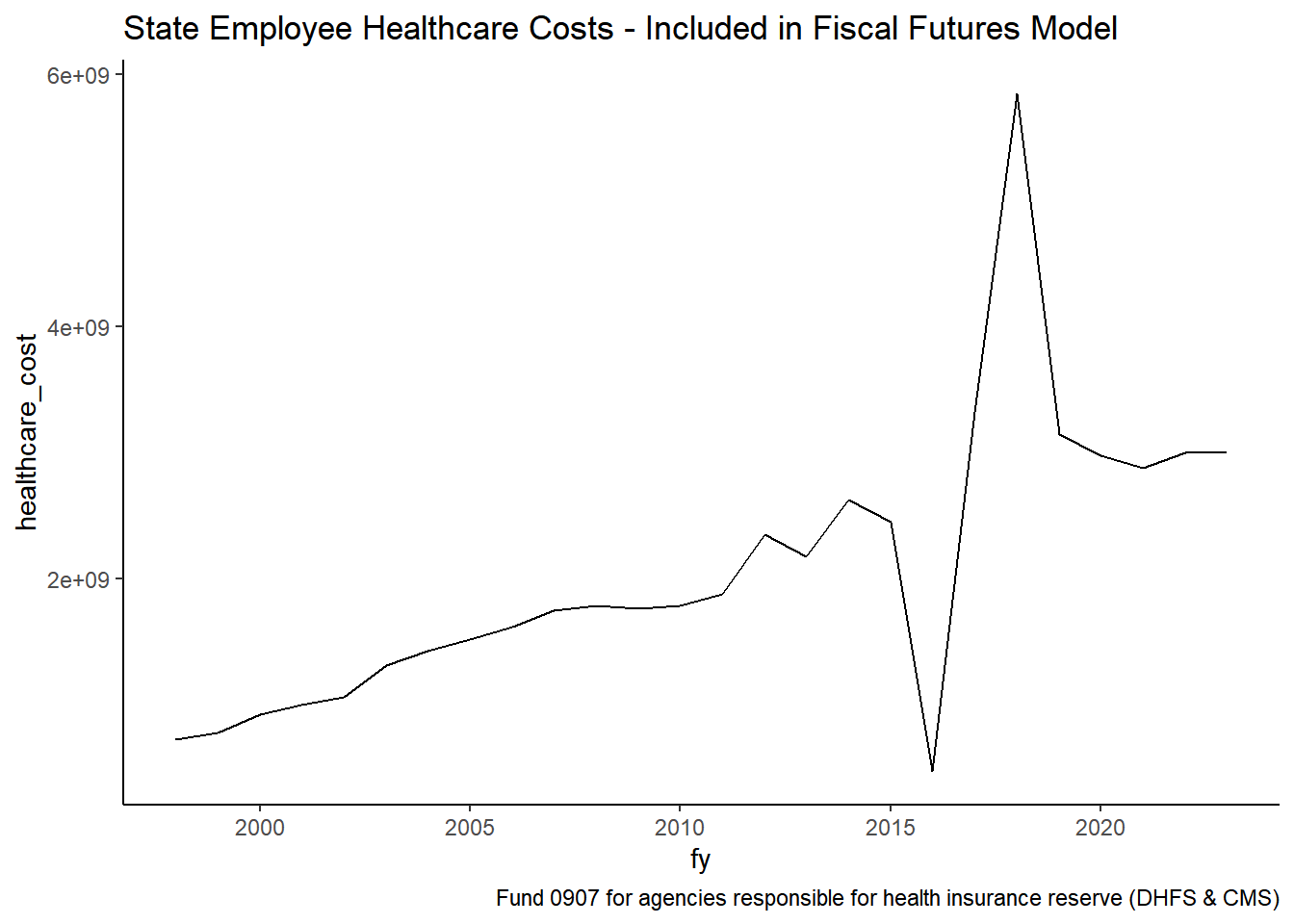
1.1.4 State employee healthcare costs
Coding healthcare costs was quite difficult. Over the years, State employee healthcare has been within Central Management Bureau of Benefits and Healthcare & Family Services.
If observation is a group insurance contribution, then the expenditure amount is set to $0 (essentially dropped from analysis).
Agency 416 had group insurance contributions for 1998-2005 and 2013-present. Agency 478 had group insurance contributions from 2006-2012.
FY2021 and FY2022 contributions coded with object = 1900 (lump sum) for some reason??
Why is
Code
#if observation is a group insurance contribution, then the expenditure amount is set to $0 (essentially dropped from analysis)# pretend eehc is named group_insurance_contribution or something like that# eehc coded as zero implies that it is group insurance# if eehc=0, then expenditures are coded as zero for group insurance to avoid double counting costsexp_temp <- exp_temp %>%mutate(eehc =ifelse(# group insurance contributions for 1998-2005 and 2013-present fund =="0001"& (object =="1180"| object =="1900") & agency =="416"& appr_org=="20", 0, 1) )%>%mutate(eehc =ifelse(# group insurance contributions for 2006-2012 fund =="0001"& object =="1180"& agency =="478"& appr_org=="80", 0, eehc) )%>%# group insurance contributions from road fund# coded with 1900 for some reason??mutate(eehc =ifelse( fund =="0011"& object =="1900"& agency =="416"& appr_org=="20", 0, eehc) ) %>%mutate(expenditure =ifelse(eehc=="0", 0, expenditure)) %>%mutate(agency =case_when( # turns specific items into State Employee Healthcare (agency=904) fund=="0907"& (agency=="416"& appr_org=="20") ~"904", # central management Bureau of benefits using health insurance reserve fund=="0907"& (agency=="478"& appr_org=="80") ~"904", # agency = 478: healthcare & family services using health insurance reserve - stopped using this in 2012TRUE~as.character(agency))) %>%mutate(agency_name =ifelse( agency =="904", "STATE EMPLOYEE HEALTHCARE", as.character(agency_name)),in_ff =ifelse( agency =="904", 1, in_ff),group =ifelse(agency =="904", "904", as.character(agency))) # creates group variable# Default group = agency numberhealthcare_costs <- exp_temp %>%filter(group =="904")healthcare_costs
Code
exp_temp %>%filter(group =="904") %>%group_by(fy) %>%summarise(healthcare_cost =sum(expenditure, na.rm =TRUE)) %>%ggplot() +geom_line(aes(x=fy, y=healthcare_cost)) +labs(title="State Employee Healthcare Costs - Included in Fiscal Futures Model", caption ="Fund 0907 for agencies responsible for health insurance reserve (DHFS & CMS)")
Separate transfers to local from parent agencies that come from DOR(492) or Transportation (494). Treats muni revenue transfers as expenditures, not negative revenue.
The share of certain taxes levied state-wide at a common rate and then transferred to local governments. (Purely local-option taxes levied by specific local governments with the state acting as collection agent are NOT included.)
The six corresponding revenue items are:
Local share of Personal Income Tax
Individual Income Tax Pass-Through New 2021 (source 2582).
Local share of General Sales Tax
Personal Property Replacement Tax on Business Income
Personal Property Replacement Tax on Public Utilities
Local share of Motor Fuel Tax
Transportation Renewal Fund 0952
Until Dec 18. 2022, Local CURE was being aggregated into Revenue totals since the agency was the Department of Revenue. However the $371 million expenditure is for “LOC GOVT ARPA” and the revenue source that is Local CURE is also $371 million. Since it cancels out and is just passed through the state government, I am changing changing the fund_ab_in file so that in_ff=0 for the Local CURE fund. It also inflates the department of revenue expenditures in a misleading way when the expense is actually a transfer to local governments.
Dropping Local CURE fund from analysis results in a $371 million decrease in the department of Revenue (where the Local Government ARPA transfer money). The appropriation for it was over $740 million so some will probably be rolled over to FY23 too.
In the FY21 New and Reused Funds word document, 0325 Local CURE is described as “Created as a federal trust fund. The fund is established to receive transfers from either the disaster response and recovery fund or the state cure fund of federal funds received by the state. These transfers, subject to appropriation, will provide for the administration and payment of grants and expense reimbursements to units of local government. Revenues should be under Federal Other and expenditures under Commerce and Economic Opportunity.” - I propose changing it to exclude for both.
Code
# obj_seq_type = 44910008 includes pprt transfersexp_temp <- exp_temp %>%mutate(agency =case_when(fund=="0515"& object=="4470"& type=="08"~"971", # income tax to local governments fund=="0515"& object=="4491"& type=="08"& sequence=="00"~"971", # object is shared revenue payments fund=="0802"& object=="4491"~"972", #pprt transfer fund=="0515"& object=="4491"& type=="08"& sequence=="01"~"976", #gst to local fund=="0627"& object=="4472"~"976" , # public transportation fund but no observations exist fund=="0648"& object=="4472"~"976", # downstate public transportation, but doesn't exist fund=="0515"& object=="4470"& type=="00"~"976", # object 4470 is grants to local governments object=="4491"& (fund=="0188"|fund=="0189") ~"976", fund=="0187"& object=="4470"~"976", fund=="0186"& object=="4470"~"976", object=="4491"& (fund=="0413"|fund=="0414"|fund=="0415") ~"975", #mft to local fund =="0952"~"975", # Added Sept 29 2022 AWM. Transportation Renewal MFTTRUE~as.character(agency)),agency_name =case_when(agency =="971"~"INCOME TAX 1/10 TO LOCAL", agency =="972"~"PPRT TRANSFER TO LOCAL", agency =="975"~"MFT TO LOCAL", agency =="976"~"GST TO LOCAL",TRUE~as.character(agency_name)),group =ifelse(agency>"970"& agency <"977", as.character(agency), as.character(group)))
Code
transfers_long <- exp_temp %>%filter(group =="971"|group =="972"| group =="975"| group =="976")transfers_long %>%group_by(agency_name, group, fy) %>%summarize(expenditure =sum(expenditure, na.rm=TRUE) )%>%ggplot() +geom_line(aes(x=fy, y = expenditure, color=agency_name)) +theme_classic()+theme(legend.position ="bottom", legend.title=element_blank())+labs(title ="Transfers to Local Governments", caption ="Data Source: Illinois Office of the Comptroller")transfers <- transfers_long %>%group_by(fy, group ) %>%summarize(sum_expenditure =sum(expenditure)/1000000) %>%pivot_wider(names_from ="group", values_from ="sum_expenditure", names_prefix ="exp_" )exp_temp <-anti_join(exp_temp, transfers_long)dropped_inff_0 <- exp_temp %>%filter(in_ff ==0)exp_temp <- exp_temp %>%filter(in_ff ==1) # drops in_ff = 0 funds AFTER dealing with net-revenue above
Figure 1.5: Drop Transfers from State to Local Governments
The Local Transfers from the Personal Property Replacement Tax (fund 802) increased over $2 billion from corporate income taxes alone. Personal property replacement taxes (PPRT) are revenues collected by the state of Illinois and paid to local governments to replace money that was lost by local governments when their powers to impose personal property taxes on corporations, partnerships, and other business entities were taken away.
1.1.6 Debt Service
Debt Service expenditures include interest payment on both short-term and long-term debt. We do not include escrow or principal payments.
Decision from Sept 30 2022: We are no longer including short term principal payments as a cost; only interest on borrowing is a cost. Pre FY22 and the FY21 correction, we did include an escrow payment and principle payments as costs but not bond proceeds as revenues. This caused expenditures to be inflated because we were essentially counting debt twice - the principle payment and whatever the money was spent on in other expenditure categories, which was incorrect.
Medicaid. That portion of the Healthcare and Family Services (or Public Aid in earlier years, agency code 478) budget for Medical (appr_organization code 65) for awards and grants (object codes 4400 and 4900).
State CURE will remain in the Medicaid expenditure category due to the nature of it being federal funds providing public health services and funding to locations that provide public services.
Uses same appropriation name of “HEALTHCARE PROVIDER RELIEF” and fund == 0793 and obj_seq_type == 49000000. So can defend the “mistake” of including healthcare provider relief as Medicaid expenditure.
1.1.8 Add Other Fiscal Future group codes
Code
exp_temp <- exp_temp %>%filter(in_ff ==1) %>%#mutate(agency = as.numeric(agency) ) %>%# arrange(agency)%>%mutate(group =case_when( agency>"100"& agency<"200"~"910", # legislative agency =="528"| (agency>"200"& agency<"300") ~"920", # judicial pension>0~"901", # pensions (agency>"309"& agency<"400") ~"930", # elected officers agency =="586"~"959", # create new K-12 group agency=="402"| agency=="418"| agency=="478"| agency=="444"| agency=="482"~as.character(agency), # aging, CFS, HFS, human services, public health T ~as.character(group)) ) %>%mutate(group =case_when( agency=="478"& (appr_org=="01"| appr_org =="65"| appr_org=="88") & (object=="4900"| object=="4400") ~"945", # separates CHIP from health and human services and saves it as Medicaid agency =="586"& fund =="0355"~"945", # 586 (Board of Edu) has special education which is part of medicaid# OLD CODE: agency == "586" & appr_org == "18" ~ "945", # Spec. Edu Medicaid Matching agency=="425"| agency=="466"| agency=="546"| agency=="569"| agency=="578"| agency=="583"| agency=="591"| agency=="592"| agency=="493"| agency=="588"~"941", # public safety & Corrections agency=="420"| agency=="494"| agency=="406"| agency=="557"~as.character(agency), # econ devt & infra, tollway agency=="511"| agency=="554"| agency=="574"| agency=="598"~"946", # Capital improvement agency=="422"| agency=="532"~as.character(agency), # environment & nat. resources agency=="440"| agency=="446"| agency=="524"| agency=="563"~"944", # business regulation agency=="492"~"492", # revenue agency =="416"~"416", # central management services agency=="448"& fy >2016~"416", #add DoIT to central management T ~as.character(group))) %>%mutate(group =case_when(# agency=="684" | agency=="691" ~ as.character(agency), # moved under higher education in next line. 11/28/2022 AWM agency=="692"| agency=="695"| agency =="684"|agency =="691"| (agency>"599"& agency<"677") ~"960", # higher education agency=="427"~as.character(agency), # employment security agency=="507"| agency=="442"| agency=="445"| agency=="452"|agency=="458"| agency=="497"~"948", # other departments# other boards & Commissions agency=="503"| agency=="509"| agency=="510"| agency=="565"|agency=="517"| agency=="525"| agency=="526"| agency=="529"| agency=="537"| agency=="541"| agency=="542"| agency=="548"| agency=="555"| agency=="558"| agency=="559"| agency=="562"| agency=="564"| agency=="568"| agency=="579"| agency=="580"| agency=="587"| agency=="590"| agency=="527"| agency=="585"| agency=="567"| agency=="571"| agency=="575"| agency=="540"| agency=="576"| agency=="564"| agency=="534"| agency=="520"| agency=="506"| agency =="533"~"949", # non-pension expenditures of retirement funds moved to "Other Departments"# should have removed pension expenditures already from exp_temp in Pensions step above agency=="131"| agency=="275"| agency=="589"|agency=="593"|agency=="594"|agency=="693"~"948", T ~as.character(group))) %>%mutate(group_name =case_when( group =="416"~"Central Management", group =="478"~"Healthcare and Family Services", group =="482"~"Public Health", group =="900"~"NOT IN FRAME", group =="901"~"STATE PENSION CONTRIBUTION", group =="903"~"DEBT SERVICE", group =="910"~"LEGISLATIVE" , group =="920"~"JUDICIAL" , group =="930"~"ELECTED OFFICERS" , group =="940"~"OTHER HEALTH-RELATED", group =="941"~"PUBLIC SAFETY" , group =="942"~"ECON DEVT & INFRASTRUCTURE" , group =="943"~"CENTRAL SERVICES", group =="944"~"BUS & PROFESSION REGULATION" , group =="945"~"MEDICAID" , group =="946"~"CAPITAL IMPROVEMENT" , group =="948"~"OTHER DEPARTMENTS" , group =="949"~"OTHER BOARDS & COMMISSIONS" , group =="959"~"K-12 EDUCATION" , group =="960"~"UNIVERSITY EDUCATION" , group == agency ~as.character(group),TRUE~"Check name"),year = fy)exp_temp %>%filter(group_name =="Check name")
All expenditures recoded but not aggregated: Allows for inspection of individual expenditures within larger categories. This stage of the data is extremely useful for investigating how individual items have been coded before they are aggregated into larger categories.
1.2 Modify Revenue data
Revenue Categories NOT included in Fiscal Futures:
- 32. Garnishment-Levies. (State is fiduciary, not beneficiary.)
- 45. Student Fees-Universities. (Excluded from state-level budget.)
- 51. Retirement Contributions (of individuals and non-state entities).
- 66. Proceeds, Investment Maturities. (Not sustainable flow.)
- 72. Bond Issue Proceeds. (Not sustainable flow.)
- 75. Inter-Agency Receipts.
- 79. Cook County Intergovernmental Transfers. (State is not beneficiary.)
- 98. Prior Year Refunds.
- 99. Statutory Transfers.
All Other Sources
Expanded to include the following smaller sources:
- 30. Horse Racing Taxes & Fees.
- 60. Other Grants and Contracts.
- 63. Investment Income.
For aggregating revenue, use the rev_1998_2022 dataframe, join the funds_ab_in_2022 file to it, and then join the ioc_source_type file to the dataset. Remember: You need to update the funds_ab_in and ioc_source_type file every year!
Code
# recodes old agency numbers to consistent agency numberrev_temp <- rev_temp %>%mutate(agency =case_when( (agency=="438"| agency=="475"|agency =="505") ~"440",# financial institution & professional regulation &# banks and real estate --> coded as financial and professional reg agency =="473"~"588", # nuclear safety moved into IEMA (agency =="531"| agency =="577") ~"532", # coded as EPA (agency =="556"| agency =="538") ~"406", # coded as agriculture agency =="560"~"592", # IL finance authority (fire trucks and agriculture stuff)to state fire marshal agency =="570"& fund =="0011"~"494", # city of Chicago road fund to transportationTRUE~ (as.character(agency))))
1.2.1 Federal to State Transfers
For an deeper look at federal revenue to Illinois, Chapter 12.
The Fiscal Futures model focuses on sustainable revenue sources. To understand our fiscal gap and outlook, we need to exclude these one time revenues. GOMB has emphasized that they have allocated COVID dollars to one time expenditures (unemployment trust fund, budget stabilization fund, etc.). The fiscal gap, graphs,and CAGRs have been recalculated in the [Drop COVID Dollars] section below.
NOTE: The code chunk below only drops revenue sources with the source name of “Federal Stimulus Package” (which is the State and Local CURE revenue). Additional federal money went into other funds during the beginning of pandemic. Many departments saw increased grants and received other funds (e.g. funds)
Insurance premiums for employees is coded below but it is NOT used in the fiscal futures model. Employee and employer premiums are considered rev_51 and dropped from analysis in later step.
0120 = ins prem-option life
0120 = ins prem-optional life/univ
0347 = optional health - HMO
0348 = optional health - dental
0349 = optional health - univ/local SI
0350 = optional health - univ/local
0351 = optional health - retirement
0352 = optional health - retirement SI
0353 = optional health - retire/dental
0354 = optional health - retirement hmo
2199-2209 = various HMOs, dental, health plans from Health Insurance Reserve (fund)
Code
#collect optional insurance premiums to fund 0907 for use in eehc expenditure rev_temp <- rev_temp %>%mutate(#variable not used in aggregates, but could be interesting for other purposesemployee_premiums =ifelse(fund=="0907"& (source=="0120"| source=="0121"| (source>"0345"& source<"0357")|(source>"2199"& source<"2209")), 1, 0),# adds more rev_type codesrev_type =case_when( fund =="0427"~"12", # pub utility tax fund =="0742"| fund =="0473"~"24", # insurance and fees fund =="0976"~"36",# receipts from rev producing fund =="0392"|fund =="0723"~"39", # licenses and fees fund =="0656"~"78", #all other rev sourcesTRUE~as.character(rev_type)))# if not mentioned, then rev_type as it was# # optional insurance premiums = employee insurance premiums# emp_premium <- rev_temp %>%# group_by(fy, employee_premiums) %>%# summarize(employee_premiums_sum = sum(receipts)/1000000) %>%# filter(employee_premiums == 1) %>%# rename(year = fy) %>% # select(-employee_premiums)emp_premium_long <- rev_temp %>%filter(employee_premiums ==1)# 381 observations have employee premiums == 1# drops employee premiums from revenue# rev_temp <- rev_temp %>% filter(employee_premiums != 1)# should be dropped in next step since rev_type = 51
Note: In FY21, employee premiums were subtracted from state healthcare costs on the expenditure side to calculate a “Net Healthcare Cost” but that methodology has been discontinued. Totals were practically unchanged: revenue from employee premiums is also very small.
1.2.3 Transfers in and Out:
Then other excluded revenue types are also dropped.
Drops Blank, Student Fees, Retirement contributions, proceeds/investments, bond issue proceeds, interagency receipts, cook IGT, Prior year refunds:
Code
rev_temp <- rev_temp %>%filter(in_ff ==1) %>%mutate(local =ifelse(is.na(local), 0, local)) %>%# drops all revenue observations that were coded as "local == 1"filter(local !=1)# 1175 doesnt exist?in_from_out <-c("0847", "0867", "1175", "1176", "1177", "1178", "1181", "1182", "1582", "1592", "1745", "1982", "2174", "2264")# what does this actually include:# all are items with rev_type = 75 originally. in_out_df <- rev_temp %>%mutate(infromout =ifelse(source %in% in_from_out, 1, 0)) %>%filter(infromout ==1)rev_temp <- rev_temp %>%mutate(rev_type_new =ifelse(source %in% in_from_out, "76", rev_type))# if source contains any of the codes in in_from_out, code them as 76 (all other rev).# I end up excluding rev_76 in later steps
Code
# revenue types to dropdrop_type <-c("32", "45", "51", "66", "72", "75", "76", "79", "98", "99")# drops Blank, Student Fees, Retirement contributions, proceeds/investments,# bond issue proceeds, interagency receipts, cook IGT, Prior year refunds.rev_temp <- rev_temp %>%filter(!rev_type_new %in% drop_type)# keep observations that do not have a revenue type mentioned in drop_typetable(rev_temp$rev_type_new)
# combines smallest 4 categories to to "Other"# they were the 4 smallest in past years, are they still the 4 smallest? rev_temp <- rev_temp %>%mutate(rev_type_new =ifelse(rev_type=="30"| rev_type=="60"| rev_type=="63"| rev_type_new =="76", "78", rev_type_new))#table(rev_temp$rev_type_new) # check workexp_temp <- exp_temp %>%filter(in_ff ==1)write_csv(exp_temp, paste0("data/FY", current_year, " Files/exp_fy", current_year, "_recoded.csv"))write_csv(rev_temp, paste0("data/FY", current_year, " Files/rev_fy", current_year, "_recoded.csv"))
1.3 Pivoting and Merging
1.3.1 Revenues
Code
ff_rev <- rev_temp %>%group_by(rev_type_new, fy) %>%summarize(sum_receipts =sum(receipts, na.rm=TRUE)/1000000 ) %>%pivot_wider(names_from ="rev_type_new", values_from ="sum_receipts", names_prefix ="rev_")# ff_rev<- left_join(ff_rev, tax_refund)#ff_rev <- left_join(ff_rev, pension2_fy22, by=c("fy" = "year"))#ff_rev <- left_join(ff_rev, eehc2_amt) ff_rev <-mutate_all(ff_rev, ~replace_na(.,0))# # ff_rev <- ff_rev %>%# mutate(rev_02 = rev_02 - ref_02,# rev_03 = rev_03 - ref_03,# rev_06 = rev_06 - ref_06,# rev_09 = rev_09 - ref_09,# rev_21 = rev_21 - ref_21,# rev_24 = rev_24 - ref_24,# rev_35 = rev_35 - ref_35# # # rev_78new = rev_78 #+ pension_amt #+ eehc# ) %>% # select(-c(ref_02:ref_35, rev_99, rev_NA, rev_76# #, ref_CHECK#, pension_amt , rev_76,# # , eehc# ))# # ff_rev#noproblem <- c(0) # if ref_CHECK = $0, then there is no problem. :) # if((sum(ff_rev$ref_CHECK) == 0 )){# # ff_rev <- ff_rev %>%# # # # mutate(rev_02 = rev_02 - ref_02,# # rev_03 = rev_03 - ref_03,# # rev_06 = rev_06 - ref_06,# # rev_09 = rev_09 - ref_09,# # rev_21 = rev_21 - ref_21,# # rev_24 = rev_24 - ref_24,# # rev_35 = rev_35 - ref_35# # ) %>% # select(-c(ref_02:ref_35, # rev_99, # rev_76, # ref_CHECK # )) # }else{"You have a problem! Check what revenue items did not have rev codes (causing it to be coded as rev_NA) or the check if there were refunds that were not assigned revenue codes (tax_refunds_long objects)"}ff_rev %>%mutate_all(., ~round(.,digits=0))
Since I already pivot_wider()ed the table in the previous code chunk, I now change each column’s name by using rename() to set new variable names. Ideally the final dataframe would have both the variable name and the variable label but I have not done that yet.
1.3.2 Expenditures
Create exp_970 for all local government transfers (exp_971 + exp_972 + exp_975 + exp_976).
Table 1.3: Final Expenditure Categories, with Fiscal Futures Grouped Expenditure Categories
2 Graphs and Tables
Create total revenues and total expenditures only:
after aggregating expenditures and revenues, pivoting wider, then I want to drop the columns that I no longer want and then pivot_longer(). After pivoting_longer() and creating rev_long and exp_long, expenditures and revenues are in the same format and can be combined together for the totals and gap each year.
Code
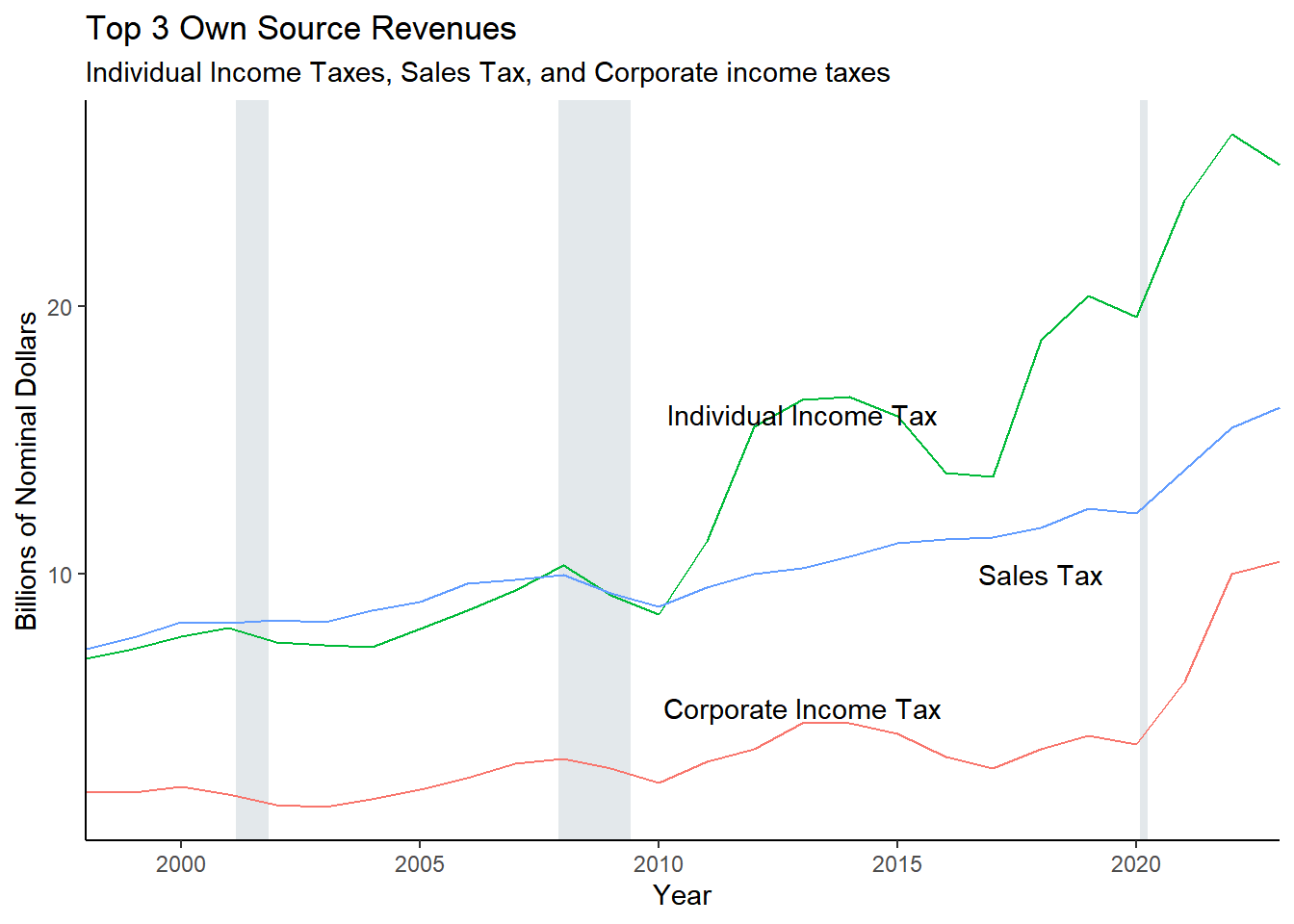
rev_long <-pivot_longer(ff_rev, rev_02:rev_78, names_to =c("type","Category"), values_to ="Dollars", names_sep ="_") %>%rename(Year = fy) %>%mutate(Category_name =case_when( Category =="02"~"INDIVIDUAL INCOME TAXES" , Category =="03"~"CORPORATE INCOME TAXES" , Category =="06"~"SALES TAXES" , Category =="09"~"MOTOR FUEL TAX" , Category =="12"~"PUBLIC UTILITY TAXES" , Category =="15"~"CIGARETTE TAXES" , Category =="18"~"LIQUOR GALLONAGE TAXES" , Category =="21"~"INHERITANCE TAX" , Category =="24"~"INSURANCE TAXES&FEES&LICENSES" , Category =="27"~"CORP FRANCHISE TAXES & FEES" , Category =="30"~"HORSE RACING TAXES & FEES", # in Other Category =="31"~"MEDICAL PROVIDER ASSESSMENTS" , Category =="32"~"GARNISHMENT-LEVIES" , # dropped Category =="33"~"LOTTERY RECEIPTS" , Category =="35"~"OTHER TAXES" , Category =="36"~"RECEIPTS FROM REVENUE PRODUCING", Category =="39"~"LICENSES, FEES & REGISTRATIONS" , Category =="42"~"MOTOR VEHICLE AND OPERATORS" , Category =="45"~"STUDENT FEES-UNIVERSITIES", # dropped Category =="48"~"RIVERBOAT WAGERING TAXES" , Category =="51"~"RETIREMENT CONTRIBUTIONS" , # dropped Category =="54"~"GIFTS AND BEQUESTS", Category =="57"~"FEDERAL OTHER" , Category =="58"~"FEDERAL MEDICAID", Category =="59"~"FEDERAL TRANSPORTATION" , Category =="60"~"OTHER GRANTS AND CONTRACTS", #other Category =="63"~"INVESTMENT INCOME", # other Category =="66"~"PROCEEDS,INVESTMENT MATURITIES" , #dropped Category =="72"~"BOND ISSUE PROCEEDS", #dropped Category =="75"~"INTER-AGENCY RECEIPTS ", #dropped Category =="76"~"TRANSFER IN FROM OUT FUNDS", #other Category =="78"~"ALL OTHER SOURCES" , Category =="79"~"COOK COUNTY IGT", #dropped Category =="98"~"PRIOR YEAR REFUNDS", #dropped T ~"Check Me!" ) )%>%mutate(Category_name =str_to_title(Category_name)) #%>% # uncomment this only after you have made sure that # you have no extra unknown revenue sources!!# select(-rev_NA)exp_long <-pivot_longer(ff_exp, exp_402:exp_970 , names_to =c("type", "Category"), values_to ="Dollars", names_sep ="_") %>%rename(Year = fy ) %>%mutate(Category_name =case_when( Category =="402"~"AGING" , Category =="406"~"AGRICULTURE", Category =="416"~"CENTRAL MANAGEMENT", Category =="418"~"CHILDREN AND FAMILY SERVICES", Category =="420"~"COMMERCE AND ECONOMIC OPPORTUNITY", Category =="422"~"NATURAL RESOURCES" , Category =="426"~"CORRECTIONS", Category =="427"~"EMPLOYMENT SECURITY" , Category =="444"~"HUMAN SERVICES" , Category =="448"~"Innovation and Technology", # AWM added fy2022 Category =="478"~"FAMILY SERVICES net Medicaid", Category =="482"~"PUBLIC HEALTH", Category =="492"~"REVENUE", Category =="494"~"TRANSPORTATION" , Category =="532"~"ENVIRONMENTAL PROTECT AGENCY" , Category =="557"~"IL STATE TOLL HIGHWAY AUTH" , Category =="684"~"IL COMMUNITY COLLEGE BOARD", Category =="691"~"IL STUDENT ASSISTANCE COMM" , Category =="900"~"NOT IN FRAME", Category =="901"~"STATE PENSION CONTRIBUTION", Category =="903"~"DEBT SERVICE", Category =="904"~"State Employee Healthcare", Category =="910"~"LEGISLATIVE" , Category =="920"~"JUDICIAL" , Category =="930"~"ELECTED OFFICERS" , Category =="940"~"OTHER HEALTH-RELATED", Category =="941"~"PUBLIC SAFETY" , Category =="942"~"ECON DEVT & INFRASTRUCTURE" , Category =="943"~"CENTRAL SERVICES", Category =="944"~"BUS & PROFESSION REGULATION" , Category =="945"~"MEDICAID" , Category =="946"~"CAPITAL IMPROVEMENT" , Category =="948"~"OTHER DEPARTMENTS" , Category =="949"~"OTHER BOARDS & COMMISSIONS" , Category =="959"~"K-12 EDUCATION" , Category =="960"~"UNIVERSITY EDUCATION", Category =="970"~"Local Govt Transfers", T ~"CHECK ME!") ) %>%mutate(Category_name =str_to_title(Category_name))write_csv(exp_long, paste0("data/FY", current_year, " Files/expenditures_recoded_long", current_year, ".csv"))write_csv(rev_long, paste0("data/FY", current_year, " Files/revenue_recoded_long", current_year, ".csv") )# combine revenue and expenditures into one data frameaggregated_totals_long <-rbind(rev_long, exp_long)aggregated_totals_long %>%mutate(`Dollars (Millions)`=round(Dollars, digits =0)) %>%select(-Dollars) %>%select(Year, Category_name, `Dollars (Millions)`, type, Category)
Table 2.1: Long Version of Data that has Revenue and Expenditures in One Dataframe
Code
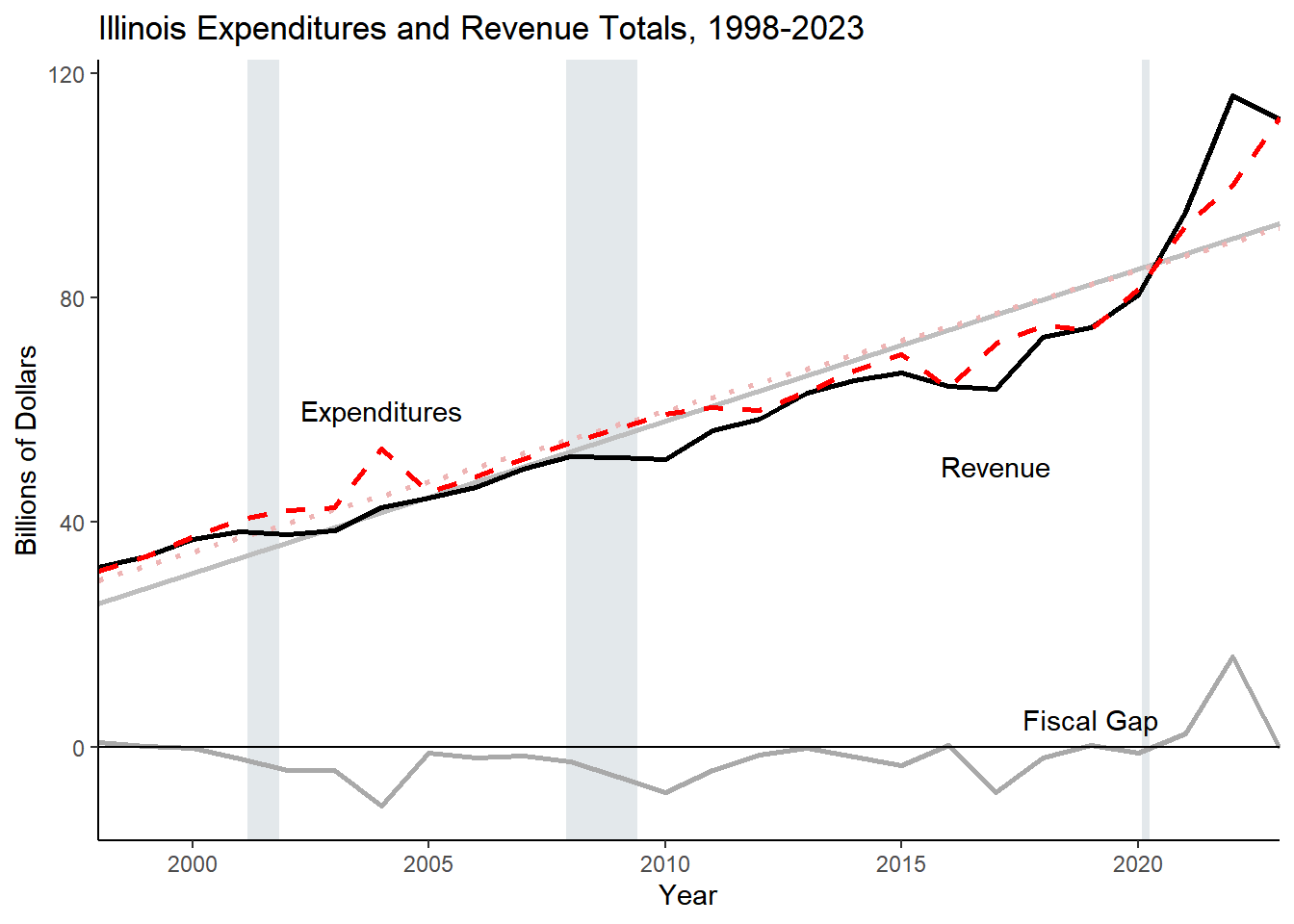
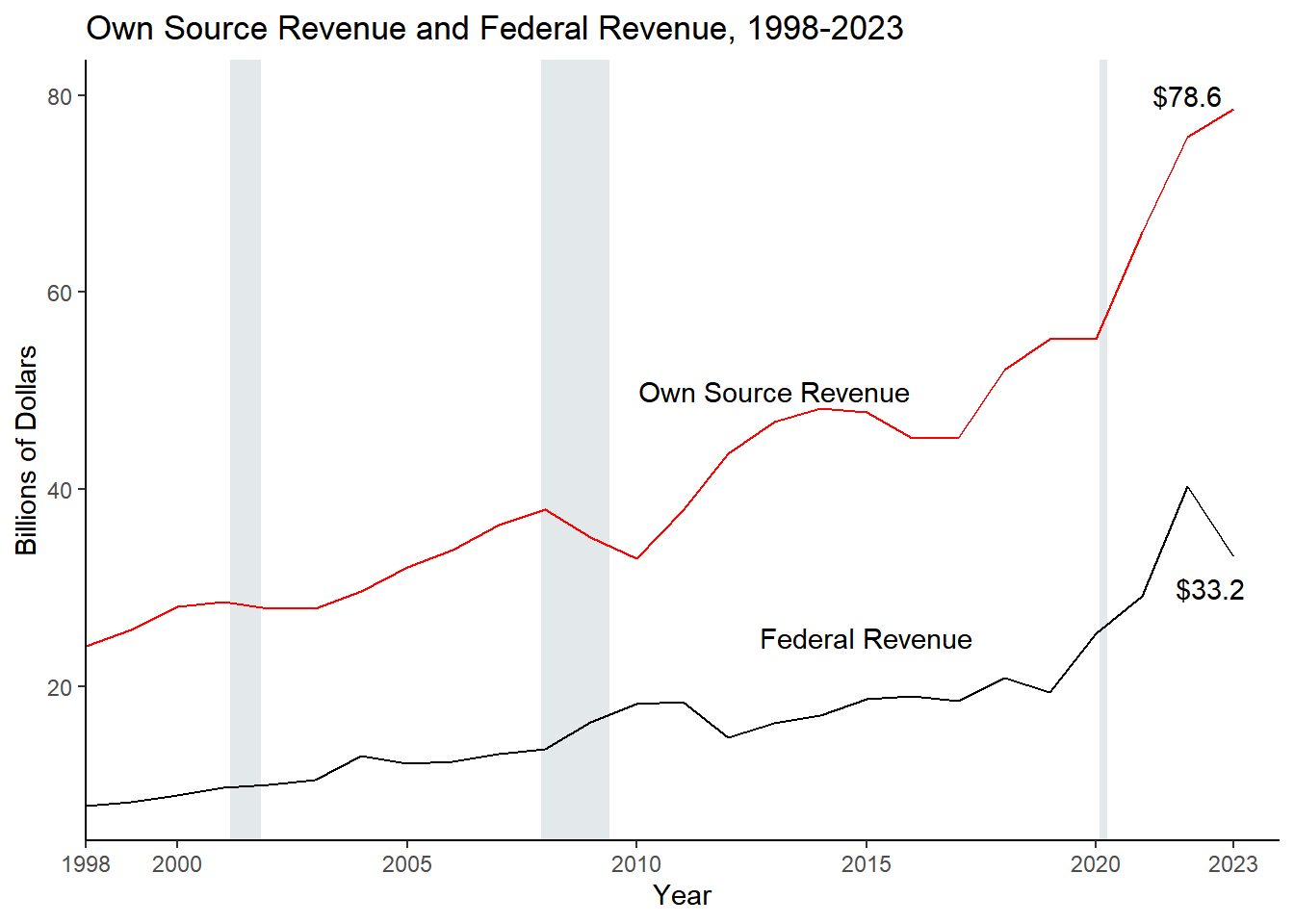
year_totals <- aggregated_totals_long %>%group_by(type, Year) %>%summarize(Dollars =sum(Dollars, na.rm =TRUE)) %>%pivot_wider(names_from ="type", values_from = Dollars) %>%rename(Expenditures = exp,Revenue = rev) %>%mutate(`Fiscal Gap`= Revenue - Expenditures)# %>% arrange(desc(Year))# creates variable for the Gap each yearyear_totals %>%mutate_all(., ~round(., digits =0)) %>%kbl(caption ="Fiscal Gap for each Fiscal Year ($ Millions)") %>%kable_styling(bootstrap_options =c("striped")) %>%kable_classic() %>%add_footnote(c("Values include State CURE dollars (SLFRF)"))
Table 2.2: Fiscal Gap for each Fiscal Year ($ Millions)
Year
Expenditures
Revenue
Fiscal Gap
1998
31246
32030
785
1999
33851
33966
115
2000
37348
37051
-297
2001
40365
38286
-2079
2002
42073
37922
-4151
2003
42614
38453
-4161
2004
53026
42612
-10414
2005
45363
44306
-1056
2006
48062
46170
-1892
2007
51132
49494
-1637
2008
54174
51643
-2531
2009
56752
51466
-5286
2010
59272
51197
-8075
2011
60425
56304
-4121
2012
59867
58422
-1444
2013
63289
63102
-188
2014
66968
65269
-1699
2015
69944
66590
-3354
2016
63934
64155
220
2017
71730
63660
-8070
2018
74975
73015
-1961
2019
74409
74638
229
2020
81609
80589
-1020
2021
92892
95206
2315
2022
100073
116061
15989
2023
111978
111774
-203
2024
115008
115129
120
a Values include State CURE dollars (SLFRF)
Graphs made from aggregated_totals_long dataframe.
Code
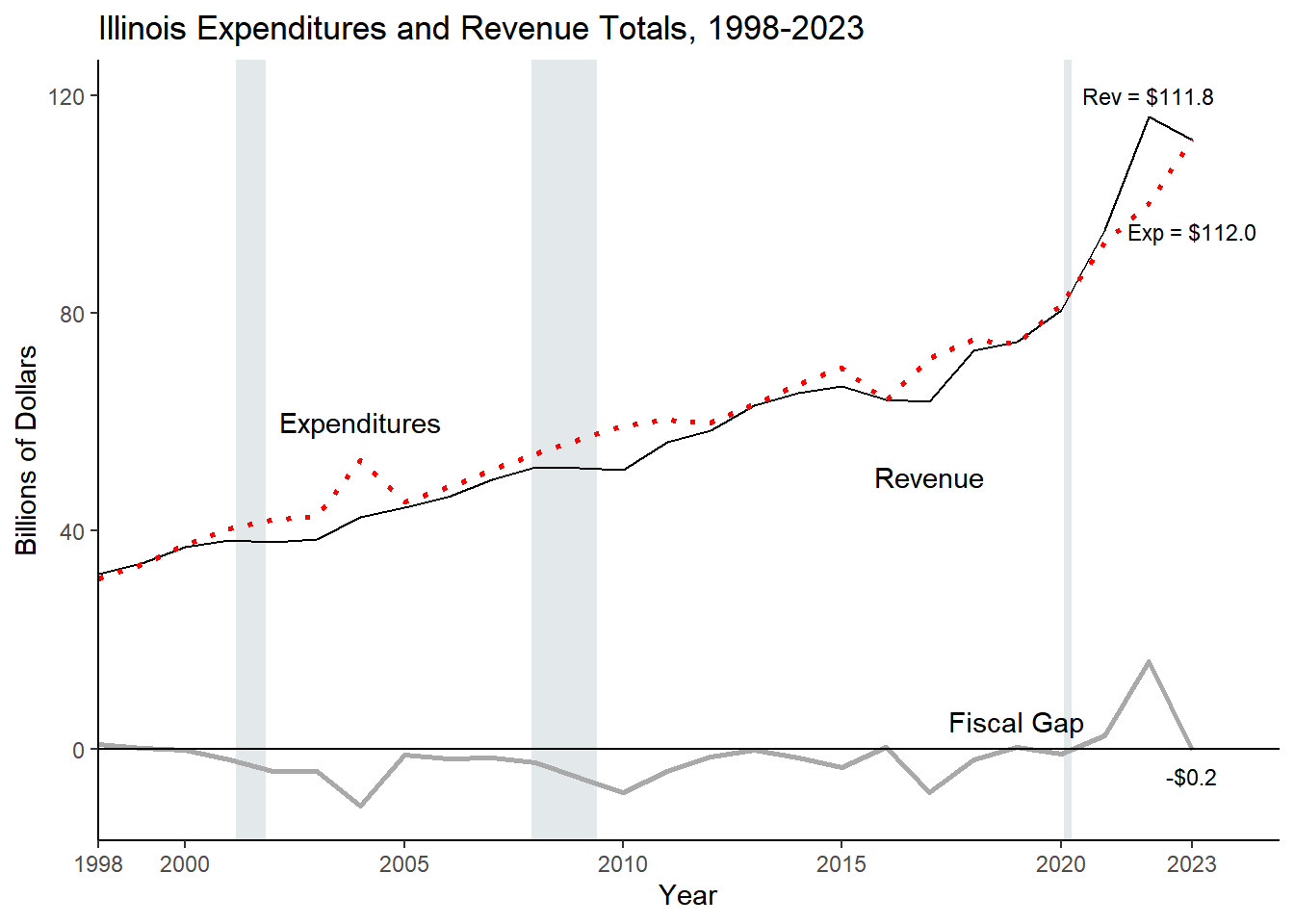
annotation <-data.frame(x =c(2004, 2017, 2019),y =c(60, 50, 5), label =c("Expenditures","Revenue", "Fiscal Gap"))annotation_nums <-data.frame(x =c(2023, 2022, 2023),y =c(95, 120, -5), label =c("Exp = $112.0","Rev = $111.8", "-$0.2"))## Dashed line versions for expenditures: library(cmapplot)fiscal_gap <-ggplot(data = year_totals, aes(x=Year, y = Revenue/1000)) +geom_recessions(text =FALSE, update = recessions)+# geom_smooth adds regression line, graphed first so it appears behind line graphgeom_smooth(aes(x = Year, y = Revenue/1000), color ="gray", alpha =0.7, method ="lm", se =FALSE) +# scale_linetype_manual(values="dashed")+geom_smooth(aes(x = Year, y = Expenditures/1000), color ="rosybrown2", linetype ="dotted", method ="lm", se =FALSE, alpha =0.7) +# line graph of revenue and expendituresgeom_line(aes(x = Year, y = Revenue/1000), color ="Black", size=1) +geom_line(aes(x = Year, y = Expenditures/1000, linetype ="dashed"), color ="red", lwd=1) +geom_line(aes(x = Year, y = (`Fiscal Gap`/1000)), color ="darkgray", lwd =1) +geom_hline(yintercept =0) +geom_text(data = annotation, aes(x=x, y=y, label=label))+# labelstheme_classic() +theme(legend.position ="none")+scale_linetype_manual(values =c("dashed", "dashed")) +scale_x_continuous(expand =c(0,0)) +# scale_y_continuous(labels = comma)+xlab("Year") +ylab("Billions of Dollars") +ggtitle("Illinois Expenditures and Revenue Totals")fiscal_gap# annotation_billions <- data.frame(# x = c(2004, 2017, 2019),# y = c(60, 50, 5), # label = c("Expenditures","Revenue", "Fiscal Gap"))fiscal_gap2 <-ggplot(data = year_totals, aes(x=Year, y = Revenue/1000)) +geom_recessions(text =FALSE, update = recessions)+geom_line(aes(x = Year, y = Revenue/1000), color ="Black") +geom_line(aes(x = Year, y = Expenditures/1000), color ="red", linetype ="dotted", lwd =1) +geom_line(aes(x = Year, y = (`Fiscal Gap`/1000)), color ="darkgray", lwd=1) +geom_text(data = annotation, aes(x=x, y=y, label=label))+geom_text(data = annotation_nums, aes(x = x, y = y, label = label), size =3) +theme_classic() +theme(legend.position ="none",panel.background =element_rect(fill='transparent'), #transparent panel bgplot.background =element_rect(fill='transparent', color=NA), #transparent plot bgpanel.grid.major =element_blank(), #remove major gridlinespanel.grid.minor =element_blank(), #remove minor gridlineslegend.background =element_rect(fill='transparent'), #transparent legend bg )+# scale_linetype_manual(values = c("dashed", "dotted")) +geom_hline(yintercept =0) +scale_y_continuous(labels = comma)+scale_x_continuous(expand =c(0,0), limits =c(1998, current_year+1), breaks =c(1998, 2000, 2005, 2010, 2015, 2020, current_year) ) +xlab("Year") +ylab("Billions of Dollars") +ggtitle("Illinois Expenditures and Revenue Totals")fiscal_gap2
Each year, you need to increase the cagr value by 1. The value should be the (current year - 1998). For FY23, this is 2023-1998 = 25. So all cagr values that were 24 will be changed to 25.
Code
# This works for one variable at a timecagr_max <-calc_cagr(exp_long, 26) %>%# group_by(Category) %>%summarize(cagr_max =round(sum(cagr*100, na.rm =TRUE), 2))# doesn't need to be changed since it is just pre-covid cagr_precovid <- exp_long %>%filter(Year <=2019) %>%calc_cagr(21) %>%summarize(cagr_21 =round(sum(cagr*100, na.rm =TRUE), 2))# Update year in the filter() and summarize() commands to current year.cagr_10 <-calc_cagr(exp_long, 10) %>%filter(Year == current_year) %>%summarize(cagr_10 =case_when(Year == current_year ~round(sum(cagr*100, na.rm =TRUE), 2)))cagr_5 <-calc_cagr(exp_long, 5) %>%filter(Year == current_year) %>%summarize(cagr_5 =case_when(Year == current_year ~round(sum(cagr*100, na.rm =TRUE), 2)))cagr_3 <-calc_cagr(exp_long, 3) %>%filter(Year == current_year) %>%summarize(cagr_3 =case_when(Year == current_year ~round(sum(cagr*100, na.rm =TRUE), 2)))cagr_2 <-calc_cagr(exp_long, 2) %>%filter(Year == current_year) %>%summarize(cagr_2 =case_when(Year == current_year ~round(sum(cagr*100, na.rm =TRUE), 2)))cagr_1 <-calc_cagr(exp_long, 1) %>%filter(Year == current_year) %>%summarize(cagr_1 =case_when(Year == current_year ~round(sum(cagr*100, na.rm =TRUE), 2)))CAGR_expenditures_summary_tot <-data.frame(cagr_1, cagr_2, cagr_3, cagr_5, cagr_10, cagr_max ) %>%select(-c(Category_name.1, Category_name.2, Category_name.3, Category_name.4, Category_name.5 )) %>%rename("Expenditure Category"= Category_name, "1 Year CAGR"= cagr_1, "2 Year CAGR"= cagr_2, "3 Year CAGR"= cagr_3, "5 Year CAGR"= cagr_5, "10 Year CAGR"= cagr_10, "26 Year CAGR"= cagr_max )move_to_last <-function(df, n) df[c(setdiff(seq_len(nrow(df)), n), n), ]CAGR_expenditures_summary_tot <-move_to_last(CAGR_expenditures_summary_tot, 29 ) #CAGR_expenditures_summary_tot <- select(CAGR_expenditures_summary_tot, -1) CAGR_expenditures_summary_tot %>%kbl(caption ="CAGR Calculations for All Expenditure Categories" , row.names=FALSE) %>%kable_classic() %>%row_spec(31, bold = T, color ="black", background ="gray")
Table 3.1: Expenditure Category CAGRs with Total CAGR (Ordered Alphabetically)
Table 3.2: Revenue Category CAGRs with Total CAGR (Ordered Alphabetically)
CAGR Calculations for All Revenue Sources (Ordered Alphabetical)
Revenue Category
1 Year CAGR
2 Year CAGR
3 Year CAGR
5 Year CAGR
10 Year CAGR
26 Year CAGR
Cigarette Taxes
-9.80
-8.27
-8.26
-1.65
-1.93
1.64
Corp Franchise Taxes & Fees
-9.97
-3.05
-14.03
-3.85
-0.01
2.10
Corporate Income Taxes
-20.82
-9.01
11.48
15.79
6.47
5.92
Federal Medicaid
5.80
5.95
6.79
12.12
9.19
7.40
Federal Other
-3.60
-26.44
4.43
12.03
4.96
4.04
Federal Transportation
11.66
13.46
-0.27
11.62
3.11
4.08
Gifts And Bequests
16.60
14.87
17.76
17.03
15.15
11.69
Individual Income Taxes
8.17
1.76
4.52
6.05
5.10
5.48
Inheritance Tax
24.82
1.98
11.73
10.07
8.54
3.60
Insurance Taxes&Fees&Licenses
0.14
4.27
1.55
4.84
3.82
6.40
Licenses, Fees & Registrations
14.12
11.66
6.05
14.82
7.04
8.18
Liquor Gallonage Taxes
-1.63
-1.39
-0.10
0.92
1.07
6.74
Lottery Receipts
3.06
7.38
2.66
3.89
1.86
2.55
Medical Provider Assessments
6.19
7.83
4.46
12.81
6.05
8.32
Motor Fuel Tax
9.84
5.67
5.79
15.88
8.11
3.02
Motor Vehicle And Operators
2.51
1.24
-1.09
0.47
0.81
3.06
Other Taxes
4.07
8.44
24.44
13.59
13.67
7.75
Public Utility Taxes
-0.26
0.97
1.68
-0.48
-0.10
0.72
Receipts From Revenue Producing
16.36
12.35
9.14
3.07
4.40
5.62
Riverboat Wagering Taxes
3.44
6.36
26.93
-3.08
-2.74
2.10
Sales Taxes
1.25
3.03
5.73
5.69
4.42
3.22
All Other Sources
11.94
29.86
32.42
19.87
10.55
6.30
Total
3.00
-0.40
6.54
9.05
5.84
5.04
Update all years in mutate() commands so that they all go up by 1:
Code
revenue_change2 <- rev_long %>%filter(Year >= past_year) %>%pivot_wider(names_from = Year , values_from = Dollars, names_prefix ="Dollars_") %>%mutate("FY Current FY ($ billions)"=round(Dollars_2024/1000, digits =1),"FY Past FY ($ billions)"=round(Dollars_2023/1000, digits =1),"1-Year Change"=round(((Dollars_2024 -Dollars_2023)/Dollars_2023*100), digits =2)) %>%left_join(CAGR_revenue_summary_tot, by =c("Category_name"="Revenue Category")) %>%arrange(-`FY Current FY ($ billions)`)%>%# filter(Category_name != "NA") %>%#select(-c(Dollars_2021, Dollars_2021, `1 Year CAGR`:`10 Year CAGR`)) %>%rename( "26-Year CAGR"=`26 Year CAGR`, "Revenue Category"= Category_name ) %>%select(-c(Dollars_2023, Dollars_2024, `1 Year CAGR`:`10 Year CAGR`)) revenue_change2 <-move_to_last(revenue_change2,7)revenue_change2 <-move_to_last(revenue_change2,1)revenue_change2 %>%filter(!is.na(`Revenue Category`)) %>%kbl(caption ="Table 1. Yearly Change in Revenue", row.names =FALSE) %>%kable_classic() %>%row_spec(23, bold = T, color ="black", background ="gray")
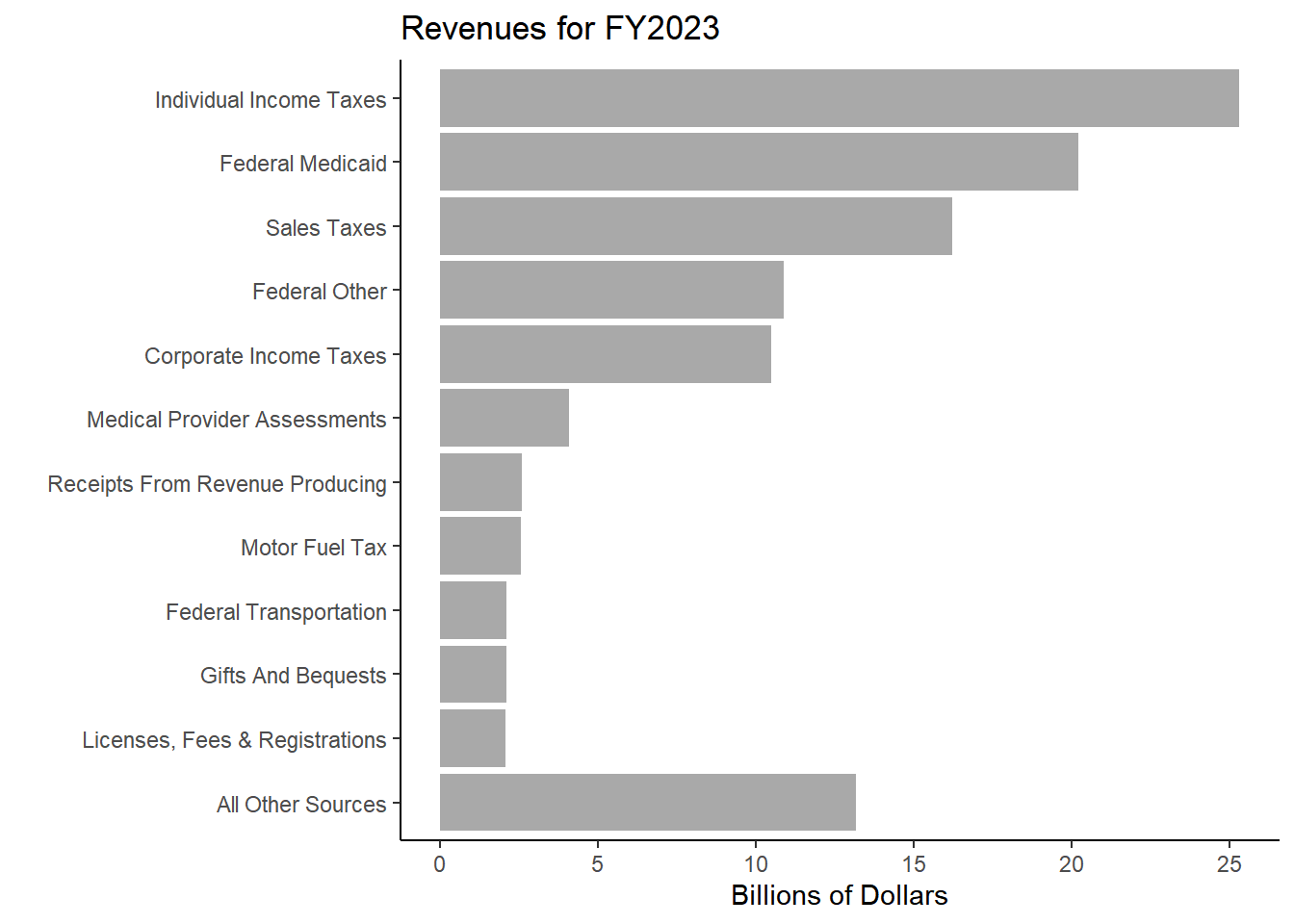
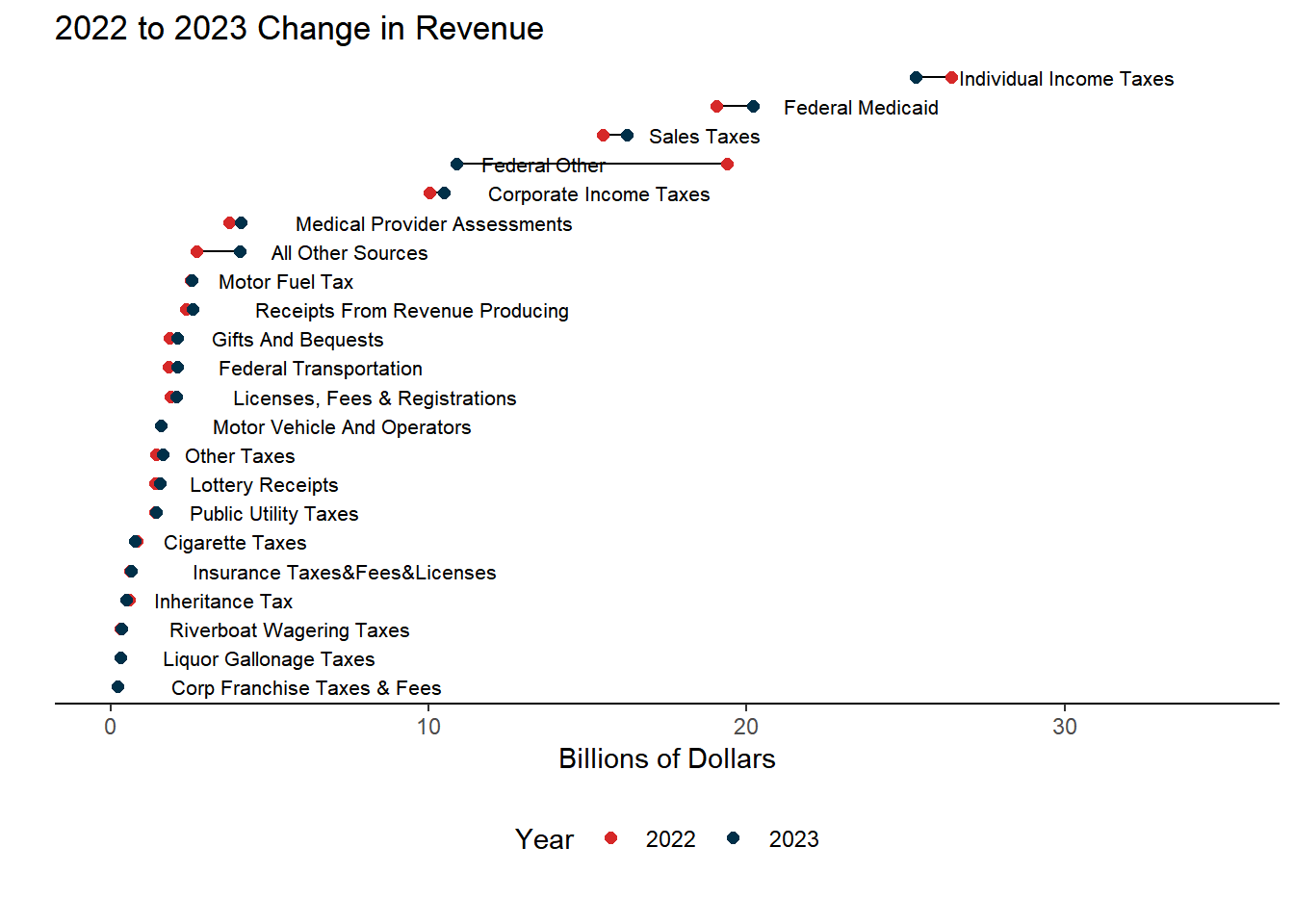
Table 1. Yearly Change in Revenue
Revenue Category
FY Current FY ($ billions)
FY Past FY ($ billions)
1-Year Change
26-Year CAGR
Individual Income Taxes
27.4
25.3
8.17
5.48
Federal Medicaid
21.4
20.2
5.80
7.40
Sales Taxes
16.4
16.2
1.25
3.22
Federal Other
10.5
10.9
-3.60
4.04
Corporate Income Taxes
8.3
10.5
-20.82
5.92
Medical Provider Assessments
4.3
4.1
6.19
8.32
Receipts From Revenue Producing
3.0
2.6
16.36
5.62
Motor Fuel Tax
2.8
2.6
9.84
3.02
Federal Transportation
2.4
2.1
11.66
4.08
Gifts And Bequests
2.4
2.1
16.60
11.69
Licenses, Fees & Registrations
2.4
2.1
14.12
8.18
Other Taxes
1.7
1.6
4.07
7.75
Lottery Receipts
1.6
1.6
3.06
2.55
Motor Vehicle And Operators
1.6
1.6
2.51
3.06
Public Utility Taxes
1.4
1.4
-0.26
0.72
Cigarette Taxes
0.7
0.8
-9.80
1.64
Insurance Taxes&Fees&Licenses
0.7
0.7
0.14
6.40
Inheritance Tax
0.6
0.5
24.82
3.60
Riverboat Wagering Taxes
0.4
0.3
3.44
2.10
Liquor Gallonage Taxes
0.3
0.3
-1.63
6.74
Corp Franchise Taxes & Fees
0.2
0.2
-9.97
2.10
All Other Sources
4.6
4.1
11.94
6.30
Total
115.1
111.8
3.00
5.04
Code
expenditure_change2 <- exp_long %>%#select(-c(type,Category)) %>%filter(Year >= past_year) %>%pivot_wider(names_from = Year , values_from = Dollars, names_prefix ="Dollars_") %>%mutate("FY 2024 ($ billions)"=round(Dollars_2024/1000, digits =1),"FY 2023 ($ billions)"=round(Dollars_2023/1000, digits =1),"1-Year Change"=round((Dollars_2024 -Dollars_2023)/Dollars_2023*100, digits =2) )%>%left_join(CAGR_expenditures_summary_tot, by =c("Category_name"="Expenditure Category")) %>%arrange(-`FY 2024 ($ billions)`)%>%select(-c(Dollars_2024, Dollars_2023, `1 Year CAGR`:`10 Year CAGR`)) %>%rename( "26-Year CAGR"=`26 Year CAGR`, "Expenditure Category"= Category_name )expenditure_change2 <-move_to_last(expenditure_change2, 1)expenditure_change2 %>%filter(!is.na(`Expenditure Category`)) %>%kbl(caption ="Table 2. Yearly Change in Expenditures - All FF Categories, Ordered from Largest to Smallest Expenditure Amount", row.names =FALSE) %>%kable_classic() %>%row_spec(31, bold = T, color ="black", background ="gray")
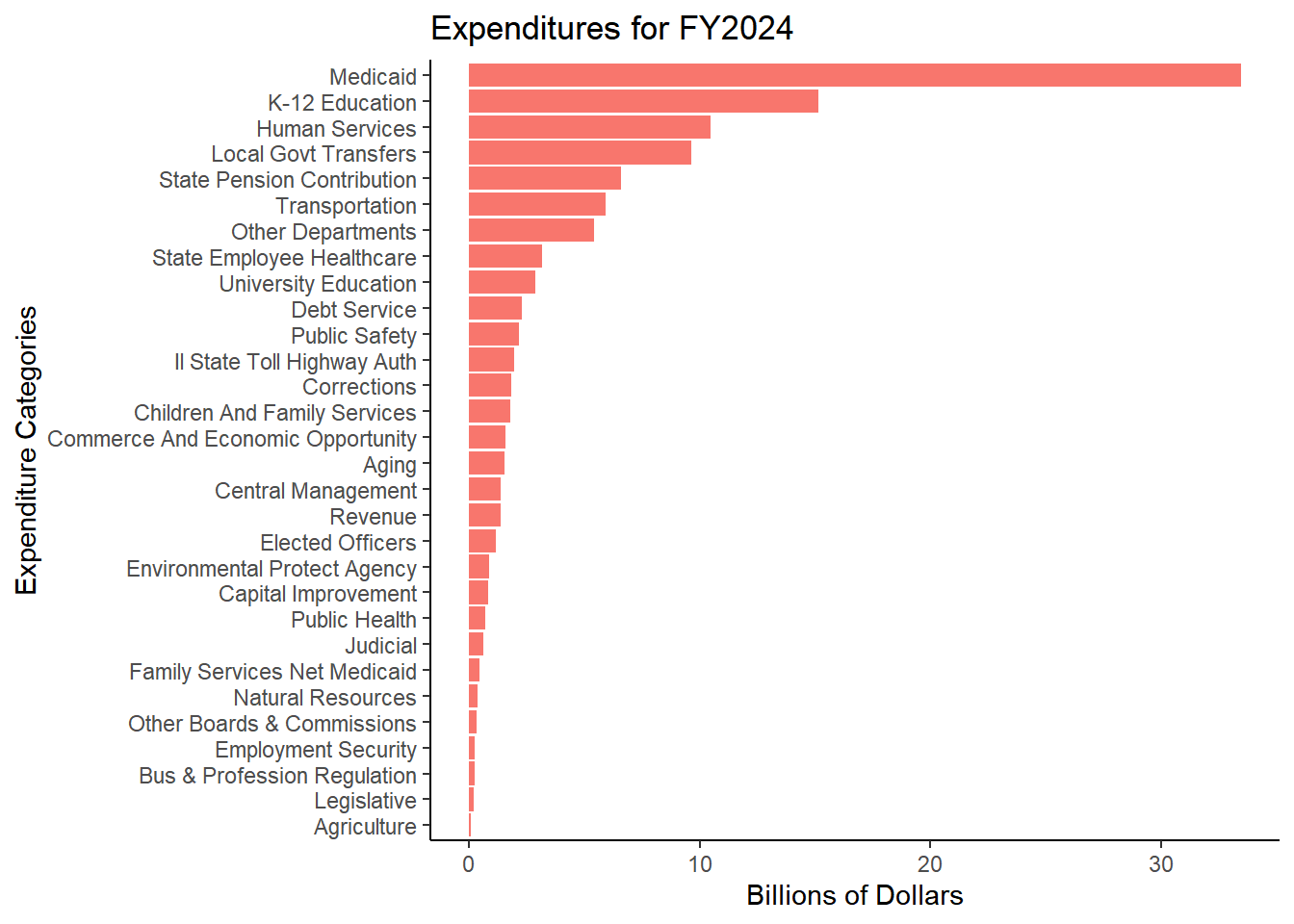
Table 2. Yearly Change in Expenditures - All FF Categories, Ordered from Largest to Smallest Expenditure Amount
Expenditure Category
FY 2024 ($ billions)
FY 2023 ($ billions)
1-Year Change
26-Year CAGR
Medicaid
33.4
32.4
3.19
7.27
K-12 Education
15.1
14.7
3.03
4.30
State Pension Contribution
11.0
11.0
-0.88
9.91
Human Services
10.4
8.8
18.59
3.87
Local Govt Revenue Sharing
9.7
10.9
-11.43
4.01
Transportation
5.6
5.1
11.72
4.16
State Employee Healthcare
3.2
3.0
5.34
5.80
University Education
2.9
2.5
13.04
1.26
Debt Service
2.3
2.0
17.27
6.15
Public Safety
2.2
1.7
25.25
6.45
Tollway
2.0
1.9
4.38
6.69
Children And Family Services
1.8
1.6
13.71
1.28
Corrections
1.8
1.7
7.26
2.51
Community Development
1.6
1.5
7.49
4.90
Other Departments
1.6
1.9
-17.18
5.39
Aging
1.5
1.4
11.77
7.88
Central Management
1.4
1.4
2.41
4.70
Revenue
1.4
3.1
-55.89
4.51
Elected Officers
1.2
1.1
12.25
4.23
Environmental Protect Agency
0.9
0.6
43.50
4.08
Capital Improvement
0.8
0.6
27.10
4.58
Public Health
0.7
0.8
-4.87
6.01
Judicial
0.6
0.6
5.58
3.51
Healthcare & Fam Ser Net Of Medicaid
0.4
0.4
9.85
5.35
Natural Resources
0.4
0.3
18.48
2.44
Employment Security
0.3
0.3
-1.89
1.60
Other Boards & Commissions
0.3
0.3
6.50
5.11
Bus & Profession Regulation
0.2
0.2
10.31
1.21
Legislative
0.2
0.2
2.42
5.10
Agriculture
0.1
0.1
22.69
1.51
Total
115.0
112.0
2.71
5.14
3.1 Summary Tables - Largest Categories
The 10 largest revenue sources and 15 largest expenditure sources remain separate categories and all other smaller sources/expenditures are combined into “All Other Revenues (Expenditures)”. These condensed tables are typically used in the Fiscal Futures articles. They were manually created in past years but this hopefully automates the process a bit until final formatting stages.
take ff_rev and ff_exp data frames, which were in wide format, pivot them longer and mutate the Category_name variable to nicer labels. Keep largest categories separate and aggregate the rest.
You need to manually comment out the categories that are not the largest each year. Check and compare to the previous years largest categories!
Code
exp_totals <- ff_exp %>%rowwise() %>%mutate(exp_TOTALS =sum(across(exp_402:exp_970))) # creates total column toorev_totals <- ff_rev %>%rowwise() %>%mutate(rev_TOTALS =sum(across(rev_02:rev_78)))rev_long_majorcats <-pivot_longer(rev_totals, rev_02:rev_TOTALS, names_to =c("type","Category"), values_to ="Dollars", names_sep ="_") %>%rename(Year = fy) %>%mutate(Category_name =case_when( Category =="02"~"Income Tax" , Category =="03"~"Corporate Income Tax" , Category =="06"~"Sales Tax" , Category =="09"~"Motor Fuel Taxes" ,# Category == "12" ~ "PUBLIC UTILITY TAXES, gross of PPRT" ,# Category == "15" ~ "CIGARETTE TAXES" ,# Category == "18" ~ "LIQUOR GALLONAGE TAXES" ,# Category == "21" ~ "INHERITANCE TAX" ,# Category == "24" ~ "INSURANCE TAXES&FEES&LICENSES, net of refunds " ,# Category == "27" ~ "CORP FRANCHISE TAXES & FEES" ,# Category == "30" ~ "HORSE RACING TAXES & FEES", # in Other Category =="31"~"Medical Provider Assessments" ,# Category == "32" ~ "GARNISHMENT-LEVIES" , # dropped# Category == "33" ~ "LOTTERY RECEIPTS" ,# Category == "35" ~ "OTHER TAXES" , Category =="36"~"Receipts from Revenue Producing", Category =="39"~"Licenses, Fees, Registration" ,# Category == "42" ~ "MOTOR VEHICLE AND OPERATORS" ,# Category == "45" ~ "STUDENT FEES-UNIVERSITIES", # dropped# Category == "48" ~ "RIVERBOAT WAGERING TAXES" ,# Category == "51" ~ "RETIREMENT CONTRIBUTIONS" , # dropped# Category == "54" ~ "GIFTS AND BEQUESTS", Category =="57"~"Federal Other" , Category =="58"~"Federal Medicaid Reimbursements", Category =="59"~"Federal Transportation" ,# Category == "60" ~ "OTHER GRANTS AND CONTRACTS", #other# Category == "63" ~ "INVESTMENT INCOME", # other# Category == "66" ~ "PROCEEDS,INVESTMENT MATURITIES" , #dropped# Category == "72" ~ "BOND ISSUE PROCEEDS", #dropped# Category == "75" ~ "INTER-AGENCY RECEIPTS ", #dropped# Category == "76" ~ "TRANSFER IN FROM OUT FUNDS", #other# Category == "78new" ~ "ALL OTHER SOURCES" ,# Category == "79" ~ "COOK COUNTY IGT", #dropped# Category == "98" ~ "PRIOR YEAR REFUNDS", #dropped Category =="TOTALS"~"Total Revenue", T ~"All Other Sources **"# any other Category number that was not specifically referenced is combined into Other Revenue Sources ) ) %>%select(-type, -Category) %>%# drop extra columns type and Category numbergroup_by(Year, Category_name) %>%summarise(Dollars=round(sum(Dollars),digits=2)) # revenue_wide # not actually in wide format yet. # has 10 largest rev sources separate and combined all others to Other in long data format. # creates wide version of table where each revenue source is a columnrevenue_wide_majorcats <- rev_long_majorcats %>%pivot_wider(names_from = Category_name, values_from = Dollars) %>%relocate("All Other Sources **", .after =last_col()) %>%relocate("Total Revenue", .after =last_col()) exp_long_majorcats <-pivot_longer(exp_totals, exp_402:exp_TOTALS , names_to =c("type", "Category"), values_to ="Dollars", names_sep ="_") %>%rename(Year = fy ) %>%mutate(Category_name =case_when(# Category == "402" ~ "Aging" ,# Category == "406" ~ "AGRICULTURE", # Category == "416" ~ "Central Management", Category =="418"~"Children & Family Services", Category =="420"~"Community Development",# Category == "422" ~ "NATURAL RESOURCES" , Category =="426"~"Corrections",# Category == "427" ~ "EMPLOYMENT SECURITY" , Category =="444"~"Human Services" ,# Category == "478" ~ "HEALTHCARE & FAM SER NET OF MEDICAID", # Category == "482" ~ "PUBLIC HEALTH", Category =="492"~"Revenue", Category =="494"~"Transportation" ,# Category == "532" ~ "ENVIRONMENTAL PROTECT AGENCY" , Category =="557"~"Tollway" ,# Category == "684" ~ "IL COMMUNITY COLLEGE BOARD", # Category == "691" ~ "IL STUDENT ASSISTANCE COMM" ,# Category == "900" ~ "NOT IN FRAME", Category =="901"~"State Pension Contribution", Category =="903"~"Debt Service", Category =="904"~"State Employee Healthcare",# Category == "910" ~ "LEGISLATIVE" ,# Category == "920" ~ "JUDICIAL" ,# Category == "930" ~ "Elected Officers" , # Category == "940" ~ "OTHER HEALTH-RELATED", Category =="941"~"Public Safety" ,# Category == "942" ~ "ECON DEVT & INFRASTRUCTURE" ,# Category == "943" ~ "CENTRAL SERVICES",# Category == "944" ~ "BUS & PROFESSION REGULATION" , Category =="945"~"Medicaid" ,# Category == "946" ~ "Capital Improvement" , # Category == "948" ~ "OTHER DEPARTMENTS" ,# Category == "949" ~ "OTHER BOARDS & COMMISSIONS" , Category =="959"~"K-12 Education" , Category =="960"~"University Education", Category =="970"~"Local Govt Revenue Sharing", Category =="TOTALS"~"Total Expenditures", T ~"All Other Expenditures **") ) %>%select(-type, -Category) %>%group_by(Year, Category_name) %>%summarise(Dollars=round(sum(Dollars),digits=2))expenditure_wide_majorcats <- exp_long_majorcats %>%pivot_wider(names_from = Category_name, values_from = Dollars) %>%relocate("All Other Expenditures **", .after =last_col()) %>%relocate("Total Expenditures", .after =last_col())# CAGR values for largest expenditure categories and combined All Other Expenditures# function for calculating the CAGRcalc_cagr <-function(df, n) { df <- exp_long_majorcats %>%#select(-type) %>%arrange(Category_name, Year) %>%group_by(Category_name) %>%mutate(cagr = ((`Dollars`/lag(`Dollars`, n)) ^ (1/ n)) -1)return(df)}# This works for one variable at a timecagr_max <-calc_cagr(exp_long_majorcats, 26) %>%# group_by(Category) %>%summarize(cagr_max =round(sum(cagr*100, na.rm =TRUE), 2))cagr23_precovid <- exp_long_majorcats %>%filter(Year <=2019) %>%calc_cagr(21) %>%summarize(cagr_21 =round(sum(cagr*100, na.rm =TRUE), 2))cagr_10 <-calc_cagr(exp_long_majorcats, 10) %>%filter(Year == current_year) %>%summarize(cagr_10 =case_when(Year == current_year ~round(sum(cagr*100, na.rm =TRUE), 2)))cagr_5 <-calc_cagr(exp_long_majorcats, 5) %>%filter(Year == current_year) %>%summarize(cagr_5 =case_when(Year == current_year ~round(sum(cagr*100, na.rm =TRUE), 2)))cagr_3 <-calc_cagr(exp_long_majorcats, 3) %>%filter(Year == current_year) %>%summarize(cagr_3 =case_when(Year == current_year ~round(sum(cagr*100, na.rm =TRUE), 2)))cagr_2 <-calc_cagr(exp_long_majorcats, 2) %>%filter(Year == current_year) %>%summarize(cagr_2 =case_when(Year == current_year ~round(sum(cagr*100, na.rm =TRUE), 2)))cagr_1 <-calc_cagr(exp_long_majorcats, 1) %>%filter(Year == current_year) %>%summarize(cagr_1 =case_when(Year == current_year ~round(sum(cagr*100, na.rm =TRUE), 2)))CAGR_expenditures_majorcats_tot <-data.frame(cagr_1, cagr_2, cagr_3, cagr_5, cagr_10, cagr_max) %>%select(-c(Category_name.1, Category_name.2, Category_name.3, Category_name.4, Category_name.5 )) %>%rename("Expenditure Category"= Category_name, "1 Year CAGR"= cagr_1, "2 Year CAGR"= cagr_2, "3 Year CAGR"= cagr_3, "5 Year CAGR"= cagr_5, "10 Year CAGR"= cagr_10,"26-Year CAGR"= cagr_max )move_to_last <-function(df, n) df[c(setdiff(seq_len(nrow(df)), n), n), ]CAGR_expenditures_majorcats_tot <-move_to_last(CAGR_expenditures_majorcats_tot, 1)CAGR_expenditures_majorcats_tot <-move_to_last(CAGR_expenditures_majorcats_tot, 14) CAGR_expenditures_majorcats_tot%>%kbl(caption ="CAGR Calculations for Largest Expenditure Categories" , row.names=FALSE) %>%kable_classic() %>%row_spec(17, bold = T, color ="black", background ="gray")# Yearly change for Top 13 largest expenditure categoriesexpenditure_change_majorcats <- exp_long_majorcats %>%filter(Year >= past_year) %>%pivot_wider(names_from = Year , values_from = Dollars, names_prefix ="Dollars_") %>%mutate("FY 2024 ($ Billions)"=round(Dollars_2024/1000, digits =1),"FY 2023 ($ Billions)"=round(Dollars_2023/1000, digits =1),"1-Year Change"=percent((Dollars_2024 -Dollars_2023)/Dollars_2023, accuracy = .1) ) %>%left_join(CAGR_expenditures_majorcats_tot, by =c("Category_name"="Expenditure Category")) %>%arrange(-`FY 2024 ($ Billions)`)%>%mutate(`26-Year CAGR`=percent(`26-Year CAGR`/100, accuracy=.1)) %>%select(-c(Dollars_2024, Dollars_2023, `1 Year CAGR`:`10 Year CAGR`)) %>%rename( "26-Year CAGR"=`26-Year CAGR`, "Expenditure Category"= Category_name )expenditure_change_majorcats <-move_to_last(expenditure_change_majorcats, 4) expenditure_change_majorcats <-move_to_last(expenditure_change_majorcats, 1)expenditure_change_majorcats %>%kbl(caption ="Yearly Change in Expenditures", row.names =FALSE, align ="l") %>%kable_classic() %>%row_spec(17, bold = T, color ="black", background ="gray")
Table 3.3: Largest Expenditure Categories with CAGRs
CAGR Calculations for Largest Expenditure Categories
Expenditure Category
1 Year CAGR
2 Year CAGR
3 Year CAGR
5 Year CAGR
10 Year CAGR
26-Year CAGR
Children & Family Services
13.71
19.69
11.25
9.24
4.74
1.28
Community Development
7.49
7.60
-1.32
22.82
4.35
4.90
Corrections
7.26
10.32
4.31
2.97
3.07
2.51
Debt Service
17.27
6.71
4.14
2.20
1.77
6.15
Human Services
18.59
20.02
16.98
13.28
6.42
3.87
K-12 Education
3.03
6.39
7.54
7.32
5.36
4.30
Local Govt Revenue Sharing
-11.43
-3.40
10.39
8.17
4.82
4.01
Medicaid
3.19
8.03
8.37
11.94
8.21
7.27
Public Safety
25.25
12.60
2.79
16.69
10.11
6.45
Revenue
-55.89
-14.06
-6.94
17.74
11.00
4.51
State Employee Healthcare
5.34
2.59
3.15
0.07
1.88
5.80
State Pension Contribution
-0.88
0.89
3.88
5.53
5.16
9.91
Tollway
4.38
-3.02
0.23
2.45
3.34
6.69
Transportation
11.72
14.29
3.19
11.81
2.80
4.16
University Education
13.04
12.79
9.34
6.97
1.95
1.26
All Other Expenditures **
5.89
13.44
7.94
8.45
4.19
4.64
Total Expenditures
2.71
7.20
7.38
9.10
5.56
5.14
Yearly Change in Expenditures
Expenditure Category
FY 2024 ($ Billions)
FY 2023 ($ Billions)
1-Year Change
26-Year CAGR
Medicaid
33.4
32.4
3.2%
7.3%
K-12 Education
15.1
14.7
3.0%
4.3%
All Other Expenditures **
10.7
10.1
5.9%
4.6%
Human Services
10.4
8.8
18.6%
3.9%
Local Govt Revenue Sharing
9.7
10.9
-11.4%
4.0%
Transportation
5.6
5.1
11.7%
4.2%
State Employee Healthcare
3.2
3.0
5.3%
5.8%
University Education
2.9
2.5
13.0%
1.3%
Debt Service
2.3
2.0
17.3%
6.2%
Public Safety
2.2
1.7
25.3%
6.4%
Tollway
2.0
1.9
4.4%
6.7%
Children & Family Services
1.8
1.6
13.7%
1.3%
Corrections
1.8
1.7
7.3%
2.5%
Community Development
1.6
1.5
7.5%
4.9%
Revenue
1.4
3.1
-55.9%
4.5%
State Pension Contribution
11.0
11.0
-0.9%
9.9%
Total Expenditures
115.0
112.0
2.7%
5.1%
Top 10 revenue sources CAGRs and Yearly Change Tables: