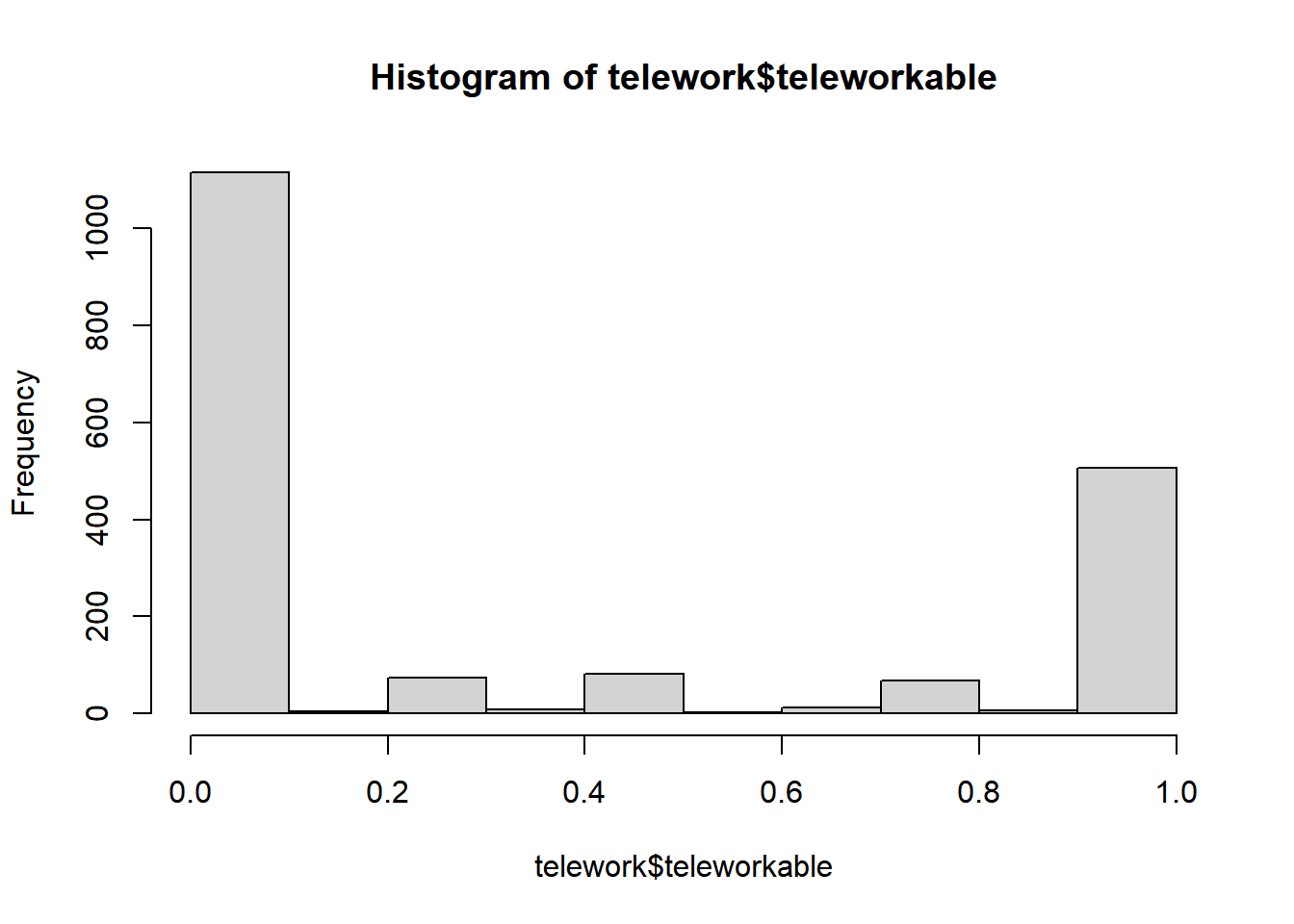
Pre 5.23.2023: 40,278 observations have occupations that indicate that they could Work from home, 67,339 responses have occupations indicating that they can not work from home, 16,136 might be able to work from home.
5.23.2023: 41,643 can wfh; 66111 no wfh possible, 15,999 some wfh
251630 observations originally in ACS 2021 and 2019 1-year samples.
123,753 observations after removing those not in the labor force and with earned incomes less than or equal to zero.
Note: Dropping groups of people using filter() from the sample will change the standard errors of estimates since it changes the sample size. Use the survey() or svy() command to drop subsets of people (like if we wanted to filter age groups). Google what commands to use to drop observations without impacting standard errors.
4.0.1 Survey Design
There are three different versions of the data: dstrata has both 2019 and 2021 data together (combined using rbind() above.) Using this combined design object makes some graphs easier, but I think it changes any standard errors used in estimate. I also made the 2019 and 2021 design strata from the the separate survey data. They all should have the same variables.
After comparing the 2021 5-year sample, it is possible to just use that 5-year sample download and use only the 2019 and 2021 years of observations. This automatically adjusts the dollar amounts to 2021 dollars. It is also possible to use Pre-COVID and post-COVID years to have even more observations. (pre-covid would be 2017,2018, and 2019, post-covid would be 2020, 2021)
Deciles were created from the strata in different ways below. Depending on age ranges kept, deciles shift slightly.
survey::svyquantile() uses the survey design to calculate deciles. These deciles that are created are slightly different than the deciles assigned using ntile(). I trust survey::svyquantile more because I know it applies the weights to observations when creating the deciles for earned income.
the ntile() decile variable is what is used to graph all decile images and for all income decile tables/calculations. incdecile_w is made using the breaks returned from the svyquantile command. This variable is weighted and used in graphs and summary tables that involve calculations of deciles using survey data.
I combine the 2019 and 2021 datasets when creating new variables and then separate them by year again before creating the survey design object for each sample year.
Last week, did this person work for pay at a job or business? (Yes or no) – Yes becomes coded as EMPSTAT = 1-Employed.
Last week, did this person do ANY work for pay, even as little as one hour?(Yes or no) – Yes becomes coded as LABFORCE = 2-Yes in the labor force.
Internet access :
At this house, apartment, or mobile home - do you or any member of this household have access to the internet?
Yes, by paying a cell phone company or Internet service provider
Yes, without paying a cell phone company of Internet service provider
No access to the Internet at this house, apartment, or mobile home
High speed internet access:
Do you or any member of this household have access to the Internet using a - b) broadband (high speed) Internet service such as cable, fiber optic, or DSL service installed in this household?
[ ]Yes [ ]No
Did WFH:
How did this person usually get to work LAST WEEK? Mark (X) ONE box for the method of transportation used for most of the distance.
Responses for Car, truck, or van, Bus, Subway or elevated rail, Long-distance train or commuter rail, Light rail, streetcar, or trolley, Ferryboat, Taxicab, Motorcycle, Bicycle, or Walked were coded as did_WFH == 0
Worked from home –> did_WFH == 1
Survey questions for INCEARN:
INCEARN = INCWAGE + INCBUS00
Total amount earned in last 12 months: Wages, salary, commissions, bonuses, tips. [Yes –> ______ ] is coded as INCWAGE value.
INCEARN includes self-employment income, INCWAGE does not.
INCWAGE does not include Farming income and self-employment income, but INCEARN does.
MARST is marital status. Used as proxy for “Lives with Partner”
MARST_1=Married, spouse present
2,3,4,5,6 = No spouse present
The survey data used was downloaded from IPUMS on April 10th 2023. Files that end with .gz are compressed versions of the .dta and .dat files. Files with .xml are for the labels of the variables. It is just the DDI that comes with the download that I renamed for clarity in Box.
4.2 Recoding and labeling variables
Code
# version with 147 variables. # uses same file as Box file named "IL_2021_1yr_ACS.dat.gz and IL_2021_1yr_ACS_datDDI.xmlddi <-read_ipums_ddi("./data/usa_00011.xml") # downloaded April 10 2023data2021 <-read_ipums_micro(ddi) # 126623 observations before any filteringdata2021 <- data2021 %>%select(YEAR, INCEARN, INCWAGE, INCTOT, TRANWORK, OCCSOC, CLASSWKR, EMPSTAT, LABFORCE, PERWT, COUNTYFIP, PUMA, PWSTATE2, AGE, STRATA, CLUSTER, RACE, HISPAN, SEX, CIHISPEED, CINETHH, MULTGEN, NCHILD, NCHLT5, MARST, FERTYR, EDUC, DEGFIELD, OCC, IND, OCC2010, METRO, CITY, HHINCOME, SERIAL,HHWT, NUMPREC, SUBSAMP, HHTYPE)
# replaces 0 with NA for variables listed. # Allows topline to calculate "Valid Percent" when it recognizes missing valuesdata <- data %>%replace_with_na(replace =list(EMPSTAT=c(0), LABFORCE=c(0), CLASSWKR =c(0),OCCSOC =c(0),CIHISPEED =c(0),CINETHH =c(0),TRANWORK =c("N/A","0"))) %>%filter(LABFORCE ==2& INCEARN >0) # in labor force and 18 years old and up abd positive earned incomes. data <- data %>%mutate(age_cat =case_when(AGE <24~"16to24", AGE >24& AGE <35~"25to34", AGE >34& AGE <45~"35to44", AGE >44& AGE <55~"45to54", AGE >54& AGE <65~"55to64", AGE >64~"65+"),sex_cat =case_when(SEX ==1~"Male", SEX ==2~"Female"))data <- data %>%mutate(white =if_else(RACE ==1, 1, 0),black =if_else(RACE ==2, 1, 0), asian =if_else(RACE %in%c(4,5,6), 1, 0),otherrace =if_else(RACE %in%c(3,7,8,9),1,0)) %>%group_by(COUNTYFIP,PUMA) %>%mutate(pct_white =sum(white)/n(),pct_black =sum(black)/n(),spouse =ifelse(1, 1, 0)) %>%ungroup() %>%mutate(race_cat =case_when( RACE ==1~"White", RACE ==2~"Black", RACE %in%c(4,5,6)~"Asian", RACE %in%c(3,7,8,9)~"Other"))## numbers used for income breaks are calculated in Income Deciles section. # created now so that the variable exists in the joined dataset before creating the survey design objectdata <- data %>%mutate(incdecile_w =case_when( INCEARN <8000~1, INCEARN >=8000& INCEARN <18000~2, INCEARN >=18000& INCEARN <26000~3, INCEARN >=26000& INCEARN <35000~4, INCEARN >=35000& INCEARN <43000~5, INCEARN >=43000& INCEARN <54000~6, INCEARN >=54000& INCEARN <68000~7, INCEARN >=68000& INCEARN <85000~8, INCEARN >=85000& INCEARN <120000~9, INCEARN >=120000~10) ) %>%## Padding FIPS code for merging with spatial geometry latermutate(county_pop_type =if_else(COUNTYFIP==0, "Rural Counties", "Urban Counties")) %>%mutate(PUMA =str_pad(PUMA, 5, pad="0"),countyFIP =str_pad(COUNTYFIP, 3, pad ="0"))data <- data %>%mutate(occ_2digits =substr(OCCSOC,1,2)) %>%mutate(occ_2dig_labels =case_when( occ_2digits %in%c(11,13,19,15,17,19,21,23,25,27,29) ~"Management, Business, Science, Arts", occ_2digits %in%c(31,32,33,34,35,36,37,38,39) ~"Service Occupations", occ_2digits %in%c(41,42,43) ~"Sales & Office Jobs", occ_2digits %in%c(45,46,47,48,49 ) ~"Natural Resources, Construction", occ_2digits %in%c(51, 52, 53) ~"Production, Transportation", occ_2digits ==55~"Military")) data <- data %>%mutate(occ_2digits =substr(OCCSOC,1,2)) %>%mutate(occ_2dig_labels_d =case_when( occ_2digits %in%c(11) ~"Management", occ_2digits %in%c(13) ~"Business & Finance", occ_2digits %in%c(15) ~"Computer, Engineering & Science", occ_2digits %in%c(17) ~"Architecture & Engineering", occ_2digits %in%c(19) ~"Life/Social Sciences", occ_2digits ==21~"Community & Social Services", occ_2digits ==23~"Legal", occ_2digits ==25~"Educational Instruction", occ_2digits ==27~"Arts, Design, Entertainainment", occ_2digits ==29~"Health Practictioners", occ_2digits ==31~"Healthcare Support", occ_2digits ==33~"Protective services", occ_2digits ==35~"Food Services", occ_2digits ==37~"Building Cleaning & Maintenance", occ_2digits ==41~"Sales", occ_2digits ==43~"Office & Administration", occ_2digits ==45~"Farm, Fish, Forest", occ_2digits ==47~"Construction & Extraction", occ_2digits ==49~"Installation, Maintenance", occ_2digits ==51~"Production", occ_2digits ==53~"Transportation & Material Moving", occ_2digits ==55~"Military",TRUE~"Other") )data <- data %>%mutate(did_wfh =if_else(TRANWORK==80, 1, 0)) # 1 = wfh, 0 = did not wfhdata <- data %>%mutate(PWSTATE2 =ifelse(PWSTATE2 ==0, NA, PWSTATE2),work_in_IL =ifelse(PWSTATE2 =="17", "In Illinois", "Out of IL"),did_wfh_labels =ifelse(did_wfh ==1, "Did WFH", "Did not WFH"),has_incearn =ifelse(INCEARN >0, 1, 0), ## has earned income = 1has_occsoc =ifelse(OCCSOC >0, 1, 0),# has occupation = 1has_incearn_labels =ifelse(INCEARN >0, "Has EarnInc", "No IncData"), ## has earned income = 1has_occsoc_labels =ifelse(OCCSOC >0, "Has Occ", "No Occ") ## OCCSOC code greater than zero coded as 1 )rm(ddi)#rm(data2019)#rm(data2021)
4.4 Teleworkable Scores
Code
# bring in the teleworkable scores based on D&N's work.telework <-read_csv("./data/teleworkable_AWM.csv")hist(telework$teleworkable)
Code
joined <-left_join(data, telework, by =c("OCCSOC"="occ_codes"))#May 22 2023, Changed 399011 occupation to 0. Was coding Nannies and Child care as teleworkable.joined <- joined %>%mutate(teleworkable =ifelse(OCCSOC =="399011"| OCCSOC =="399010", 0, teleworkable))#table(joined$teleworkable)# mostly 0's and 1's.#hist(joined$teleworkable)joined <- joined %>%mutate(CanWorkFromHome =case_when( teleworkable ==0~"No WFH", teleworkable <1~"Some WFH", teleworkable ==1~"Can WFH",TRUE~"Check Me")) %>%# keeps observations that have earned income values and are in the labor force.filter(has_incearn ==1& LABFORCE ==2) joined$CanWorkFromHome <-factor(joined$CanWorkFromHome, levels =c("No WFH", "Some WFH", "Can WFH") )table(joined$CanWorkFromHome)
#as_survey() from srvyr package## both years together: calculations using this will have incorrect standard errors# might be easier sometimes to graph together. Maybe. dstrata <- survey::svydesign(id =~CLUSTER, strata =~STRATA, weights =~PERWT, data = joined) %>%as_survey() %>%mutate(decile =ntile(INCEARN, 10))# 2019 data turned into survey itemdstrata2019 <- joined %>%filter(YEAR==2019) dstrata2019 <- survey::svydesign(id =~CLUSTER, strata =~STRATA, weights =~PERWT, data = dstrata2019) %>%as_survey() %>%mutate(decile =ntile(INCEARN, 10))dstrata2021 <- joined %>%filter(YEAR==2021) dstrata2021 <- survey::svydesign(id =~CLUSTER, strata =~STRATA, weights =~PERWT, data = dstrata2021) %>%as_survey() %>%mutate(decile =ntile(INCEARN, 10))# deciles using ntile(). Not weighted!! Close to income deciles from weighted suvey design though.
Code
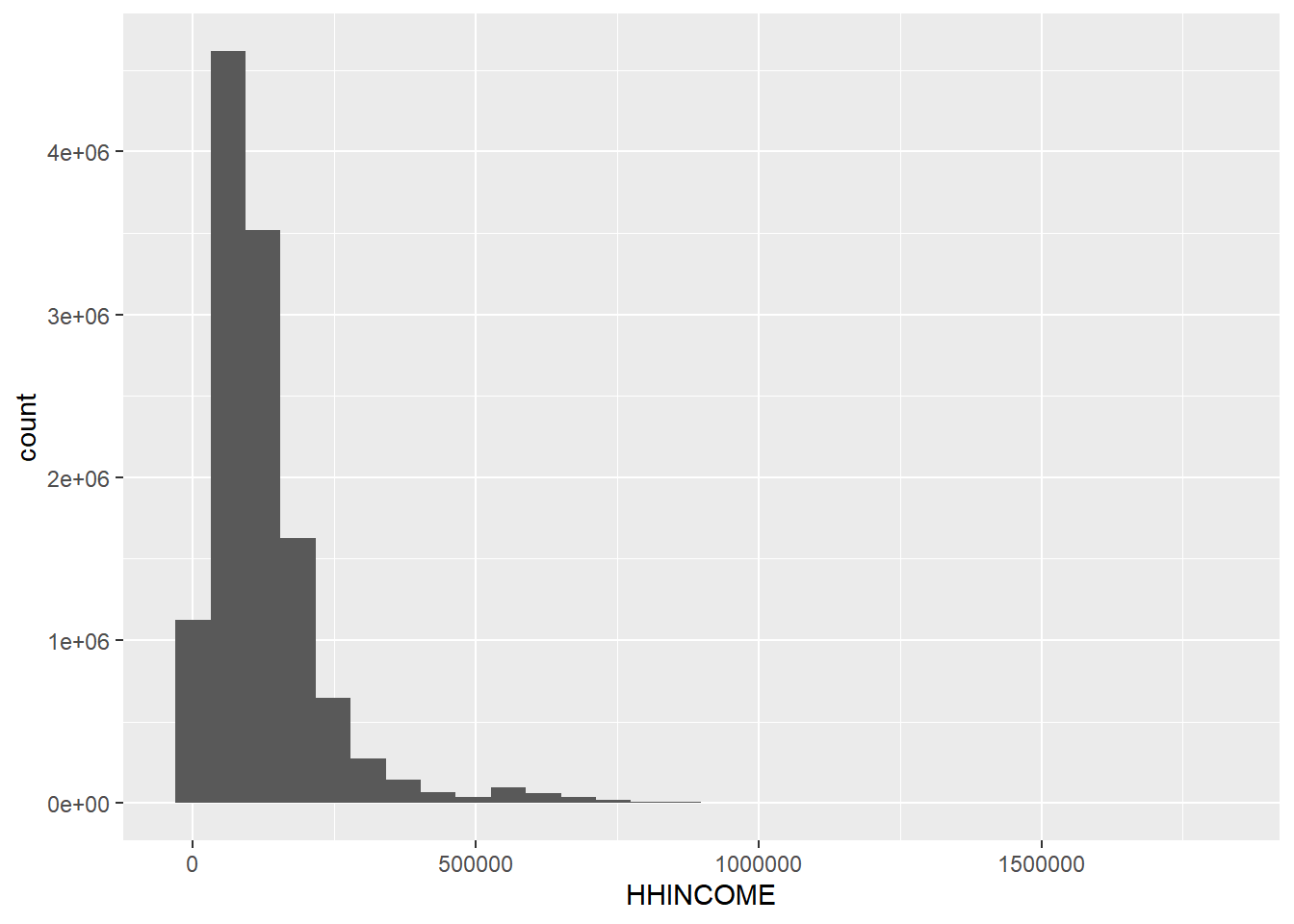
joined <- joined %>%filter(HHINCOME >0& HHINCOME!=9999999& HHINCOME !=9999998) # 105 observations joined %>%ggplot() +geom_histogram(aes(x=HHINCOME, weight = HHWT))
Code
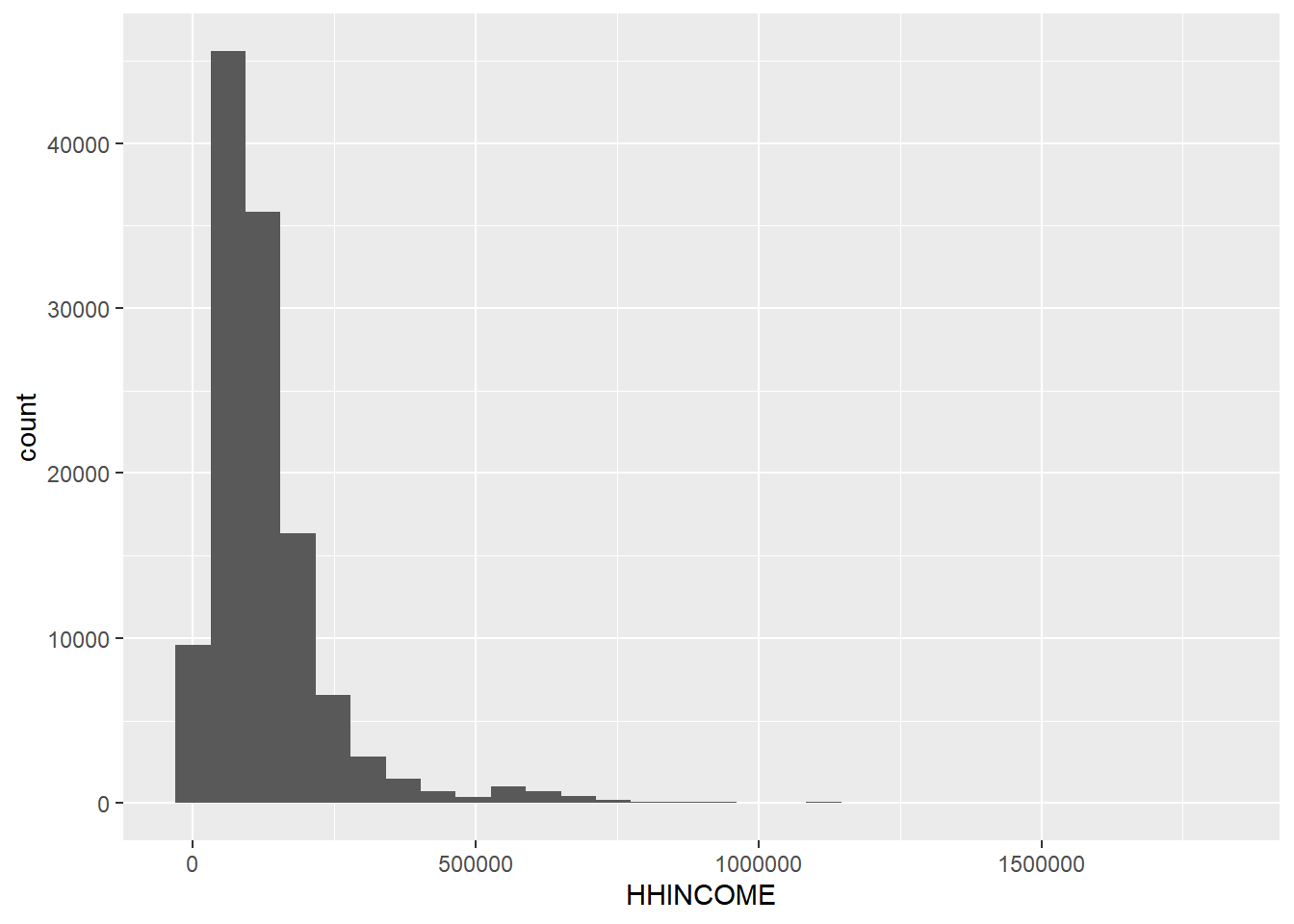
joined %>%# 122000 observations ggplot() +geom_histogram(aes(x=HHINCOME))
Code
HHdesign <- survey::svydesign(id =~CLUSTER, strata =~STRATA, weights =~HHWT, data = joined)inc_quantiles <-survey::svyquantile(~HHINCOME, design=HHdesign, quantiles =c(0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1) ,na.rm=TRUE, ci =FALSE )inc_quantiles
---editor: markdown: wrap: 72---# Getting Data**Pre 5.23.2023**: 40,278 observations have occupations that indicatethat they could Work from home, 67,339 responses have occupationsindicating that they can not work from home, 16,136 might be able towork from home.**5.23.2023**: 41,643 can wfh; 66111 no wfh possible, 15,999 some wfh251630 observations originally in ACS 2021 and 2019 1-year samples.123,753 observations after removing those not in the labor force andwith earned incomes less than or equal to zero.::: {.callout-warning appearance="simple" icon="false"}Note: Dropping groups of people using filter() from the sample willchange the standard errors of estimates since it changes the samplesize. Use the survey() or svy() command to drop subsets of people (likeif we wanted to filter age groups). Google what commands to use to dropobservations without impacting standard errors.:::### Survey DesignThere are three different versions of the data: dstrata has both 2019and 2021 data together (combined using rbind() above.) Using thiscombined design object makes some graphs easier, but I think it changesany standard errors used in estimate. I also made the 2019 and 2021design strata from the the separate survey data. They all should havethe same variables.> After comparing the 2021 5-year sample, it is possible to just use> that 5-year sample download and use only the 2019 and 2021 years of> observations. This automatically adjusts the dollar amounts to 2021> dollars. It is also possible to use Pre-COVID and post-COVID years to> have even more observations. (pre-covid would be 2017,2018, and 2019,> post-covid would be 2020, 2021)Deciles were created from the strata in different ways below. Dependingon age ranges kept, deciles shift slightly.2019 Strata by itself:\4 9000 17000 25000 32000 40000 50000 63000 80000 114000 9330002019 Strata income decile breaks (using the 2021 5-year extract):\4 9538 18016 26494 33912 42390 52988 66765 84781 121873 988757.\**Already adjusted for inflation??????**- 9000, 9400, 25000, 32000, 40000, 50000, 63000, 80000, 1140000, 949000- 8000, 18000, 26000, 35000, 43000, 54000, 68000, 85000, 120000 \::: {.callout-warning appearance="simple" icon="false"}survey::svyquantile() uses the survey design to calculate deciles. Thesedeciles that are created are slightly different than the decilesassigned using ntile(). I trust survey::svyquantile more because I knowit applies the weights to observations when creating the deciles forearned income.:::::: {.callout-important appearance="minimal" icon="false"}the ntile() decile variable is what is used to graph all decile imagesand for all income decile tables/calculations. `incdecile_w` is madeusing the breaks returned from the svyquantile command. This variable isweighted and used in graphs and summary tables that involve calculationsof deciles using survey data.:::I combine the 2019 and 2021 datasets when creating new variables andthen separate them by year again before creating the survey designobject for each sample year.```{r setup, warning=FALSE, message=FALSE, include=FALSE}library(scales)library(reldist)library(pollster)library(labelled)library(weights)library(tigris)library(ipumsr)library(srvyr)library(survey)library(tidyverse)library(naniar)library(gmodels)library(gtsummary)library(quarto)library(huxtable) # for summ() and regression output formattinglibrary(jtools)library(modelsummary)library(car)knitr::opts_chunk$set(warning=FALSE, message=FALSE)```## ACS Questions UsedIPUMS [link for Survey package](https://usa.ipums.org/usa/repwt.shtml)Survey questions for EMPSTAT & LABFORCE:1. Last week, did this person work for pay at a job or business? (Yes or no) -- Yes becomes coded as EMPSTAT = 1-Employed.2. Last week, did this person do ANY work for pay, even as little as one hour?(Yes or no) -- Yes becomes coded as LABFORCE = 2-Yes in the labor force.Internet access :3. At this house, apartment, or mobile home - do you or any member of this household have access to the internet? - Yes, by paying a cell phone company or Internet service provider - Yes, without paying a cell phone company of Internet service provider - No access to the Internet at this house, apartment, or mobile homeHigh speed internet access:4. Do you or any member of this household have access to the Internet using a - b) broadband (high speed) Internet service such as cable, fiber optic, or DSL service installed in this household?\\[\]Yes \[\]NoDid WFH:5. How did this person usually get to work LAST WEEK? Mark (X) ONE box for the method of transportation used for most of the distance. - Responses for Car, truck, or van, Bus, Subway or elevated rail, Long-distance train or commuter rail, Light rail, streetcar, or trolley, Ferryboat, Taxicab, Motorcycle, Bicycle, or Walked were coded as did_WFH == 0 - Worked from home --\> did_WFH == 1Survey questions for INCEARN:6. INCEARN = INCWAGE + INCBUS00 - Total amount earned in last 12 months: Wages, salary, commissions, bonuses, tips. \[Yes --\>\_\_\_\_\_\_\] is coded as INCWAGE value.7. INCEARN includes self-employment income, INCWAGE does not. - INCWAGE does not include Farming income and self-employment income, but INCEARN does.8. MARST is marital status. Used as proxy for "Lives with Partner" - MARST_1=Married, spouse present - 2,3,4,5,6 = No spouse presentThe survey data used was downloaded from IPUMS on April 10th 2023. Filesthat end with .gz are compressed versions of the .dta and .dat files.Files with .xml are for the labels of the variables. It is just the DDIthat comes with the download that I renamed for clarity in Box.<!--# usa_00011.xml and usa_00011.dat.gz are the same as Box files named IL_2021_1yr_ACS.dat.gz and IL_2021_1yr_ACS_datDDI.xml original xml file references the file name that it is called in the download. Either change the XML file to reference the correct .dat.gz files OR just keep track of which extracts are the same as the box file names. -->## Recoding and labeling variables```{r message=FALSE, warning = FALSE}# version with 147 variables. # uses same file as Box file named "IL_2021_1yr_ACS.dat.gz and IL_2021_1yr_ACS_datDDI.xmlddi <-read_ipums_ddi("./data/usa_00011.xml") # downloaded April 10 2023data2021 <-read_ipums_micro(ddi) # 126623 observations before any filteringdata2021 <- data2021 %>%select(YEAR, INCEARN, INCWAGE, INCTOT, TRANWORK, OCCSOC, CLASSWKR, EMPSTAT, LABFORCE, PERWT, COUNTYFIP, PUMA, PWSTATE2, AGE, STRATA, CLUSTER, RACE, HISPAN, SEX, CIHISPEED, CINETHH, MULTGEN, NCHILD, NCHLT5, MARST, FERTYR, EDUC, DEGFIELD, OCC, IND, OCC2010, METRO, CITY, HHINCOME, SERIAL,HHWT, NUMPREC, SUBSAMP, HHTYPE)``````{r message=FALSE, warning = FALSE}ddi <-read_ipums_ddi("./data/IL_2019_1yearACS_datDDI.xml") # downloaded April 10 2023data2019 <-read_ipums_micro(ddi) # 126623 observations before any filteringdata2019 <- data2019 %>%select(YEAR, INCEARN, INCWAGE, INCTOT, TRANWORK, OCCSOC, CLASSWKR, EMPSTAT, LABFORCE, PERWT, COUNTYFIP, PUMA, PWSTATE2, AGE, STRATA, CLUSTER, RACE, HISPAN, SEX, CIHISPEED, CINETHH, MULTGEN, NCHILD, NCHLT5, MARST, FERTYR, EDUC, DEGFIELD, OCC, IND, OCC2010, METRO, CITY, HHINCOME, SERIAL, HHWT, NUMPREC, SUBSAMP, HHTYPE)data <-rbind(data2019, data2021) #125,007 observations before any filtering.```## ```{r message=FALSE, warning = FALSE}# replaces 0 with NA for variables listed. # Allows topline to calculate "Valid Percent" when it recognizes missing valuesdata <- data %>%replace_with_na(replace =list(EMPSTAT=c(0), LABFORCE=c(0), CLASSWKR =c(0),OCCSOC =c(0),CIHISPEED =c(0),CINETHH =c(0),TRANWORK =c("N/A","0"))) %>%filter(LABFORCE ==2& INCEARN >0) # in labor force and 18 years old and up abd positive earned incomes. data <- data %>%mutate(age_cat =case_when(AGE <24~"16to24", AGE >24& AGE <35~"25to34", AGE >34& AGE <45~"35to44", AGE >44& AGE <55~"45to54", AGE >54& AGE <65~"55to64", AGE >64~"65+"),sex_cat =case_when(SEX ==1~"Male", SEX ==2~"Female"))data <- data %>%mutate(white =if_else(RACE ==1, 1, 0),black =if_else(RACE ==2, 1, 0), asian =if_else(RACE %in%c(4,5,6), 1, 0),otherrace =if_else(RACE %in%c(3,7,8,9),1,0)) %>%group_by(COUNTYFIP,PUMA) %>%mutate(pct_white =sum(white)/n(),pct_black =sum(black)/n(),spouse =ifelse(1, 1, 0)) %>%ungroup() %>%mutate(race_cat =case_when( RACE ==1~"White", RACE ==2~"Black", RACE %in%c(4,5,6)~"Asian", RACE %in%c(3,7,8,9)~"Other"))## numbers used for income breaks are calculated in Income Deciles section. # created now so that the variable exists in the joined dataset before creating the survey design objectdata <- data %>%mutate(incdecile_w =case_when( INCEARN <8000~1, INCEARN >=8000& INCEARN <18000~2, INCEARN >=18000& INCEARN <26000~3, INCEARN >=26000& INCEARN <35000~4, INCEARN >=35000& INCEARN <43000~5, INCEARN >=43000& INCEARN <54000~6, INCEARN >=54000& INCEARN <68000~7, INCEARN >=68000& INCEARN <85000~8, INCEARN >=85000& INCEARN <120000~9, INCEARN >=120000~10) ) %>%## Padding FIPS code for merging with spatial geometry latermutate(county_pop_type =if_else(COUNTYFIP==0, "Rural Counties", "Urban Counties")) %>%mutate(PUMA =str_pad(PUMA, 5, pad="0"),countyFIP =str_pad(COUNTYFIP, 3, pad ="0"))data <- data %>%mutate(occ_2digits =substr(OCCSOC,1,2)) %>%mutate(occ_2dig_labels =case_when( occ_2digits %in%c(11,13,19,15,17,19,21,23,25,27,29) ~"Management, Business, Science, Arts", occ_2digits %in%c(31,32,33,34,35,36,37,38,39) ~"Service Occupations", occ_2digits %in%c(41,42,43) ~"Sales & Office Jobs", occ_2digits %in%c(45,46,47,48,49 ) ~"Natural Resources, Construction", occ_2digits %in%c(51, 52, 53) ~"Production, Transportation", occ_2digits ==55~"Military")) data <- data %>%mutate(occ_2digits =substr(OCCSOC,1,2)) %>%mutate(occ_2dig_labels_d =case_when( occ_2digits %in%c(11) ~"Management", occ_2digits %in%c(13) ~"Business & Finance", occ_2digits %in%c(15) ~"Computer, Engineering & Science", occ_2digits %in%c(17) ~"Architecture & Engineering", occ_2digits %in%c(19) ~"Life/Social Sciences", occ_2digits ==21~"Community & Social Services", occ_2digits ==23~"Legal", occ_2digits ==25~"Educational Instruction", occ_2digits ==27~"Arts, Design, Entertainainment", occ_2digits ==29~"Health Practictioners", occ_2digits ==31~"Healthcare Support", occ_2digits ==33~"Protective services", occ_2digits ==35~"Food Services", occ_2digits ==37~"Building Cleaning & Maintenance", occ_2digits ==41~"Sales", occ_2digits ==43~"Office & Administration", occ_2digits ==45~"Farm, Fish, Forest", occ_2digits ==47~"Construction & Extraction", occ_2digits ==49~"Installation, Maintenance", occ_2digits ==51~"Production", occ_2digits ==53~"Transportation & Material Moving", occ_2digits ==55~"Military",TRUE~"Other") )data <- data %>%mutate(did_wfh =if_else(TRANWORK==80, 1, 0)) # 1 = wfh, 0 = did not wfhdata <- data %>%mutate(PWSTATE2 =ifelse(PWSTATE2 ==0, NA, PWSTATE2),work_in_IL =ifelse(PWSTATE2 =="17", "In Illinois", "Out of IL"),did_wfh_labels =ifelse(did_wfh ==1, "Did WFH", "Did not WFH"),has_incearn =ifelse(INCEARN >0, 1, 0), ## has earned income = 1has_occsoc =ifelse(OCCSOC >0, 1, 0),# has occupation = 1has_incearn_labels =ifelse(INCEARN >0, "Has EarnInc", "No IncData"), ## has earned income = 1has_occsoc_labels =ifelse(OCCSOC >0, "Has Occ", "No Occ") ## OCCSOC code greater than zero coded as 1 )rm(ddi)#rm(data2019)#rm(data2021)```## Teleworkable Scores```{r could-wfh}# bring in the teleworkable scores based on D&N's work.telework <-read_csv("./data/teleworkable_AWM.csv")hist(telework$teleworkable)joined <-left_join(data, telework, by =c("OCCSOC"="occ_codes"))#May 22 2023, Changed 399011 occupation to 0. Was coding Nannies and Child care as teleworkable.joined <- joined %>%mutate(teleworkable =ifelse(OCCSOC =="399011"| OCCSOC =="399010", 0, teleworkable))#table(joined$teleworkable)# mostly 0's and 1's.#hist(joined$teleworkable)joined <- joined %>%mutate(CanWorkFromHome =case_when( teleworkable ==0~"No WFH", teleworkable <1~"Some WFH", teleworkable ==1~"Can WFH",TRUE~"Check Me")) %>%# keeps observations that have earned income values and are in the labor force.filter(has_incearn ==1& LABFORCE ==2) joined$CanWorkFromHome <-factor(joined$CanWorkFromHome, levels =c("No WFH", "Some WFH", "Can WFH") )table(joined$CanWorkFromHome)table(joined$did_wfh, joined$YEAR)joined <- joined %>%filter(HHINCOME >0& HHINCOME!=9999999& HHINCOME !=9999998) # 105 observations ## Deciles checked in Income sectionjoined <- joined %>%mutate(HHincdecile_w =case_when( INCEARN <34000~1, INCEARN >=34000& INCEARN <51900~2, INCEARN >=51900& INCEARN <68000~3, INCEARN >=68000& INCEARN <83600~4, INCEARN >=83699& INCEARN <100000~5, INCEARN >=100000& INCEARN <120000~6, INCEARN >=120000& INCEARN <142400~7, INCEARN >=142400& INCEARN <175000~8, INCEARN >=175000& INCEARN <235000~9, INCEARN >=235000~10) )```## Dealing with Survey Data```{r survey-design, message = FALSE, warning=FALSE}#as_survey() from srvyr package## both years together: calculations using this will have incorrect standard errors# might be easier sometimes to graph together. Maybe. dstrata <- survey::svydesign(id =~CLUSTER, strata =~STRATA, weights =~PERWT, data = joined) %>%as_survey() %>%mutate(decile =ntile(INCEARN, 10))# 2019 data turned into survey itemdstrata2019 <- joined %>%filter(YEAR==2019) dstrata2019 <- survey::svydesign(id =~CLUSTER, strata =~STRATA, weights =~PERWT, data = dstrata2019) %>%as_survey() %>%mutate(decile =ntile(INCEARN, 10))dstrata2021 <- joined %>%filter(YEAR==2021) dstrata2021 <- survey::svydesign(id =~CLUSTER, strata =~STRATA, weights =~PERWT, data = dstrata2021) %>%as_survey() %>%mutate(decile =ntile(INCEARN, 10))# deciles using ntile(). Not weighted!! Close to income deciles from weighted suvey design though.``````{r}#| code-fold: true#| output: holdjoined <- joined %>%filter(HHINCOME >0& HHINCOME!=9999999& HHINCOME !=9999998) # 105 observations joined %>%ggplot() +geom_histogram(aes(x=HHINCOME, weight = HHWT))joined %>%# 122000 observations ggplot() +geom_histogram(aes(x=HHINCOME))HHdesign <- survey::svydesign(id =~CLUSTER, strata =~STRATA, weights =~HHWT, data = joined)inc_quantiles <-survey::svyquantile(~HHINCOME, design=HHdesign, quantiles =c(0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1) ,na.rm=TRUE, ci =FALSE )inc_quantiles# With HH Weights: 4 32900 50000 66600 82000 99000 117000 140000 171000 230000 1797000# With WRONG weights: (34000, 51900, 68000, 83600, 1e+05 120,000 142,400 175,000 235,000#Code done above when creating variables in beginning chunks.joined <- joined %>%mutate(HHincdecile_w =case_when( INCEARN <32900~1, INCEARN >=32900& INCEARN <50000~2, INCEARN >=50000& INCEARN <66600~3, INCEARN >=66600& INCEARN <82000~4, INCEARN >=82000& INCEARN <99000~5, INCEARN >=99000& INCEARN <117000~6, INCEARN >=117000& INCEARN <140000~7, INCEARN >=140000& INCEARN <171000~8, INCEARN >=171000& INCEARN <230000~9, INCEARN >=230000~10) )``````{r}save(joined, data2019, data2021, dstrata, dstrata2019, dstrata2021, file ="./data/WFH.RData")```